参考视频:https://www.imooc.com/learn/1043 https://m.imooc.com/article/details?article_id=75457 note_kafka
课程介绍
Kafka概念解析
Kafka结构设计
Kafka场景应用
Kafka高级特性
什么是kafka 什么是kafka
LinkedIn 开源
Databus 分布式数据同步系统
Cubert 高性能计算引擎
ParSeq Java异步处理框架
Kafka 分布式发布订阅消息系统,流处理平台
Kafka发展历程
LinkedIn 开发
2011年初开源,加入Apache基金会
2012年从Apache Incubator毕业
Apache顶级开源项目
Kafka的特性
可以发布和订阅且记录数据的流,类似于消息队列
数据流存储的平台,具备容错能力
在数据产生时就可以进行处理
Kafka通常被用于
kafka基本概念 Producer:数据生产者
消息和数据的生产者
向Kafka的一个topic发布消息的进程或代码或服务
Consumer:数据消费者
消息和数据的消费者
向Kafka订阅数据(topic)并且处理其发布的消息的进程或代码或服务
Consumer Group:消费者组
对于同一个topic,会广播给不同的Group
一个Group中,只有一个Consumer可以消费该消息
Broker:服务节点
Topic:主题
Partition:分区
Kafka中数据存储的基本单元
一个topic数据,会被分散存储到多个Partition
一个Partition只会存在一个Broker上
每个Partition是有序的
Replication:分区的副本
同一个Partition可能会有多个Replication
多个Replication之间数据是一样的
Replication Leader:副本的老大
一个Partition的多个Replication上
需要一个Leader负责该Partition上与Producer和Consumer交互
Replication Manager:副本的管理者
负责管理当前Broker所有分区和副本的信息
处理KafkaController发起的一些请求
副本状态的切换
添加、读取消息等
kafka概念延伸
Partition:分区
每一个Topic被切分为多个Partition
消费者数目少于或等于Partition的数目
Broker Group中的每一个Broker保存Topic的一个或多个Partition
Consumer Group中的仅有一个Consumer读取Topic的一个或多个Partition,并且是惟一的Consumer
Replication:分区的副本
当集群中有Broker挂掉的情况,系统可以主动地使Replication提供服务
系统默认设置每一个Topic的Replication系数为1,可以在创建Topic时单独设置
Replication的基本单位是Topic的Partition
所有的读和写都从Replication Leader进行,Replication Followers只是作为备份
Replication Followers必须能够及时复制Replication Leader的数据
增加容错性与可扩展性
kafka结构设计 基本结构 Kafka功能结构
Kafka数据流势
Kafka消息结构
Offset:当前消息所处于的偏移
Length:消息的长度
CRC32:校验字段,用于校验当前信息的完整性
Magic:很多分布式系统都会设计该字段,固定的数字,用于快速判定当前信息是否为Kafka消息
attributes:可选字段,消息的属性
Timestamp:时间戳
Key Length:Key的长度
Key:Key
Value Length:Value的长度
Value:Value
功能特点 Kafka特点:分布式
多分区
多副本
多订阅者
基于Zookeeper调度
Kafka特点:高性能
Kafka特点:持久性与扩展性
数据可持久化
容错性
支持在线水平扩展
消息自动平衡
kafka的应用 应用场景 Kafka应用场景
消息队列
行为跟踪
元信息监控
日志收集
流处理
事件源
持久性日志(commit log)
应用案例 Kafka简单案例
单机下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 1.下载与安装 Zookeeper下载:https://zookeeper.apache.org/releases.html#download Kafka下载:http://kafka.apache.org/downloads 安装:解压、配置环境变量 mac只需要: brew install kafka 2.Zookeeper启动 //进入zookeeper安装目录/bin ./zkServer start /usr/local/etc/kafka/zookeeper.properties //clientPort=2181 3.Kafka启动 ./kafka-server-start /usr/local/etc/kafka/server.properties //端口=9092 4.使用控制台操作生产者与消费者 创建Topic:./kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic my-kafka-topic 查看Topic:./kafka-topics --list --zookeeper localhost:2181 启动生产者:./kafka-console-producer --broker-list localhost:9092 --topic my-kafka-topic 启动消费者:./kafka-console-consumer --bootstrap-server localhost:9092 --topic my-kafka-topic --from-beginning //--from-beginning: 让消费者从头开始消费,不加这个参数就从当前生产者发出的消息开始消费 生产消息:my first msg
代码案例
生产者和消费者的配置
application.properties
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 kafka.consumer.zookeeper.connect =127.0.0.1:2181 kafka.consumer.servers =127.0.0.1:9092 kafka.consumer.enable.auto.commit =true kafka.consumer.session.timeout =6000 kafka.consumer.auto.commit.interval =100 kafka.consumer.auto.offset.reset =latest kafka.consumer.topic =my-kafka-topic kafka.consumer.group.id =machine4869 kafka.consumer.concurrency =10 kafka.producer.servers =127.0.0.1:9092 kafka.producer.retries =0 kafka.producer.batch.size =4096 kafka.producer.linger =1 kafka.producer.buffer.memory =40960 kafka.topic.default =my-kafka-topic
KafkaProducerConfig
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 package com.machine.example.kafka.config;import com.machine.example.kafka.common.MessageEntity;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.common.serialization.StringSerializer;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.annotation.EnableKafka;import org.springframework.kafka.core.DefaultKafkaProducerFactory;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.kafka.core.ProducerFactory;import org.springframework.kafka.support.serializer.JsonSerializer;import java.util.HashMap;import java.util.Map;@Configuration @EnableKafka public class KafkaProducerConfig @Value ("${kafka.producer.servers}" ) private String servers; @Value ("${kafka.producer.retries}" ) private int retries; @Value ("${kafka.producer.batch.size}" ) private int batchSize; @Value ("${kafka.producer.linger}" ) private int linger; @Value ("${kafka.producer.buffer.memory}" ) private int bufferMemory; public Map<String, Object> producerConfigs () Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, servers); props.put(ProducerConfig.RETRIES_CONFIG, retries); props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize); props.put(ProducerConfig.LINGER_MS_CONFIG, linger); props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class ) ; props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class ) ; return props; } public ProducerFactory<String, MessageEntity> producerFactory () return new DefaultKafkaProducerFactory<>(producerConfigs(), new StringSerializer(), new JsonSerializer<MessageEntity>()); } @Bean public KafkaTemplate<String, MessageEntity> kafkaTemplate () return new KafkaTemplate<>(producerFactory()); } }
KafkaConsumerConfig
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 package com.machine.example.kafka.config;import com.machine.example.kafka.common.MessageEntity;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.common.serialization.StringDeserializer;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.kafka.annotation.EnableKafka;import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;import org.springframework.kafka.config.KafkaListenerContainerFactory;import org.springframework.kafka.core.ConsumerFactory;import org.springframework.kafka.core.DefaultKafkaConsumerFactory;import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;import org.springframework.kafka.support.serializer.JsonDeserializer;import java.util.HashMap;import java.util.Map;@Configuration @EnableKafka public class KafkaConsumerConfig @Value ("${kafka.consumer.servers}" ) private String servers; @Value ("${kafka.consumer.enable.auto.commit}" ) private boolean enableAutoCommit; @Value ("${kafka.consumer.session.timeout}" ) private String sessionTimeout; @Value ("${kafka.consumer.auto.commit.interval}" ) private String autoCommitInterval; @Value ("${kafka.consumer.group.id}" ) private String groupId; @Value ("${kafka.consumer.auto.offset.reset}" ) private String autoOffsetReset; @Value ("${kafka.consumer.concurrency}" ) private int concurrency; @Bean public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, MessageEntity>> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, MessageEntity> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setConcurrency(concurrency); factory.getContainerProperties().setPollTimeout(1500 ); return factory; } private ConsumerFactory<String, MessageEntity> consumerFactory () return new DefaultKafkaConsumerFactory<>( consumerConfigs(), new StringDeserializer(), new JsonDeserializer<>(MessageEntity.class )//value ) ; } private Map<String, Object> consumerConfigs () Map<String, Object> propsMap = new HashMap<>(); propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers); propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit); propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval); propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeout); propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class ) ; propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class ) ; propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset); return propsMap; } }
生产者
SimpleProducer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 package com.machine.example.kafka.producer;import com.machine.example.kafka.common.MessageEntity;import org.apache.kafka.clients.producer.ProducerRecord;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.kafka.core.KafkaTemplate;import org.springframework.kafka.support.SendResult;import org.springframework.stereotype.Component;import org.springframework.util.concurrent.ListenableFuture;@Component public class SimpleProducer @Autowired @Qualifier ("kafkaTemplate" ) private KafkaTemplate<String, MessageEntity> kafkaTemplate; public void send (String topic, MessageEntity message) kafkaTemplate.send(topic, message); } public void send (String topic, String key, MessageEntity entity) ProducerRecord<String, MessageEntity> record = new ProducerRecord<>( topic, key, entity); long startTime = System.currentTimeMillis(); ListenableFuture<SendResult<String, MessageEntity>> future = kafkaTemplate.send(record); future.addCallback(new ProducerCallback(startTime, key, entity)); } }
ProducerCallback
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 package com.machine.example.kafka.producer;import com.google.gson.Gson;import com.machine.example.kafka.common.MessageEntity;import lombok.extern.slf4j.Slf4j;import org.apache.kafka.clients.producer.RecordMetadata;import org.springframework.kafka.support.SendResult;import org.springframework.lang.Nullable;import org.springframework.util.concurrent.ListenableFutureCallback;@Slf 4jpublic class ProducerCallback implements ListenableFutureCallback <SendResult <String , MessageEntity >> private final long startTime; private final String key; private final MessageEntity message; private final Gson gson = new Gson(); public ProducerCallback (long startTime, String key, MessageEntity message) this .startTime = startTime; this .key = key; this .message = message; } @Override public void onSuccess (@Nullable SendResult<String, MessageEntity> result) if (result == null ) { return ; } long elapsedTime = System.currentTimeMillis() - startTime; RecordMetadata metadata = result.getRecordMetadata(); if (metadata != null ) { StringBuilder record = new StringBuilder(); record.append("message(" ) .append("key = " ).append(key).append("," ) .append("message = " ).append(gson.toJson(message)).append(")" ) .append("sent to partition(" ).append(metadata.partition()).append(")" ) .append("with offset(" ).append(metadata.offset()).append(")" ) .append("in " ).append(elapsedTime).append(" ms" ); log.info(record.toString()); } } @Override public void onFailure (Throwable ex) ex.printStackTrace(); } }
消费者
SimpleConsumer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package com.machine.example.kafka.consumer;import com.google.gson.Gson;import com.machine.example.kafka.common.MessageEntity;import lombok.extern.slf4j.Slf4j;import org.springframework.kafka.annotation.KafkaListener;import org.springframework.stereotype.Component;@Slf 4j@Component public class SimpleConsumer private final Gson gson = new Gson(); @KafkaListener (topics = "${kafka.topic.default}" , containerFactory = "kafkaListenerContainerFactory" ) public void receive (MessageEntity message) log.info(gson.toJson(message)); } }
Controller
ProduceController
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package com.machine.example.kafka.controller;import com.google.gson.Gson;import com.machine.example.kafka.common.ErrorCode;import com.machine.example.kafka.common.MessageEntity;import com.machine.example.kafka.common.Response;import com.machine.example.kafka.producer.SimpleProducer;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Value;import org.springframework.web.bind.annotation.RequestBody;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestMethod;import org.springframework.web.bind.annotation.RestController;@Slf 4j@RestController @RequestMapping ("/kafka" )public class ProduceController @Autowired private SimpleProducer simpleProducer; @Value ("${kafka.topic.default}" ) private String topic; private Gson gson = new Gson(); @RequestMapping (value = "/hello" , method = RequestMethod.GET, produces = {"application/json" }) public Response sendKafka () return new Response(ErrorCode.SUCCESS, "OK" ); } @RequestMapping (value = "/send" , method = RequestMethod.POST, produces = {"application/json" }) public Response sendKafka (@RequestBody MessageEntity message) try { log.info("kafka的消息={}" , gson.toJson(message)); simpleProducer.send(topic, "key" , message); log.info("发送kafka成功." ); return new Response(ErrorCode.SUCCESS, "发送kafka成功" ); } catch (Exception e) { log.error("发送kafka失败" , e); return new Response(ErrorCode.EXCEPTION, "发送kafka失败" ); } } }
测试
kafka高级特征 消息事务 为什么要支持事务
满足“读取-处理-写入”模式
流处理需求的不断增强
不准确的数据处理的容忍度不断降低
数据传输的事务定义
最多一次:消息不会被重复发送,最多被传输一次,但也有可能一次不传输
最少一次:消息不会被漏发送,最少被传输一次,但也有可能被重复传输
精确的一次(Exactly once):不会漏传输也不会重复传输,每个消息都被传输一次且仅仅被传输一次,这是大家所期望的
事务保证
内部重试问题:Procedure幂等处理
多分区原子写入
避免僵尸实例
每个事务Procedure分配一个 transactionl. id,在进程重新启动时能够识别相同的Procedure实例
零拷贝 零拷贝简介
网络传输持久性日志块
Java Nio channel.transforTo()方法
Linux sendfile系统调用
文件传输到网络的公共数据路径
第一次拷贝:操作系统将数据从磁盘读入到内核空间的页缓存
第二次拷贝:应用程序将数据从内核空间读入到用户空间缓存中
第三次拷贝:应用程序将数据写回到内核空间到socket缓存中
第四次拷贝:操作系统将数据从socket缓冲区复制到网卡缓冲区,以便将数据经网络发出
零拷贝过程(指内核空间和用户空间的交互拷贝次数为零)
第一次拷贝:操作系统将数据从磁盘读入到内核空间的页缓存
将数据的位置和长度的信息的描述符增加至内核空间(socket缓存区)
第二次拷贝:操作系统将数据从内核拷贝到网卡缓冲区,以便将数据经网络发出
文件传输到网络的公共数据路径演变
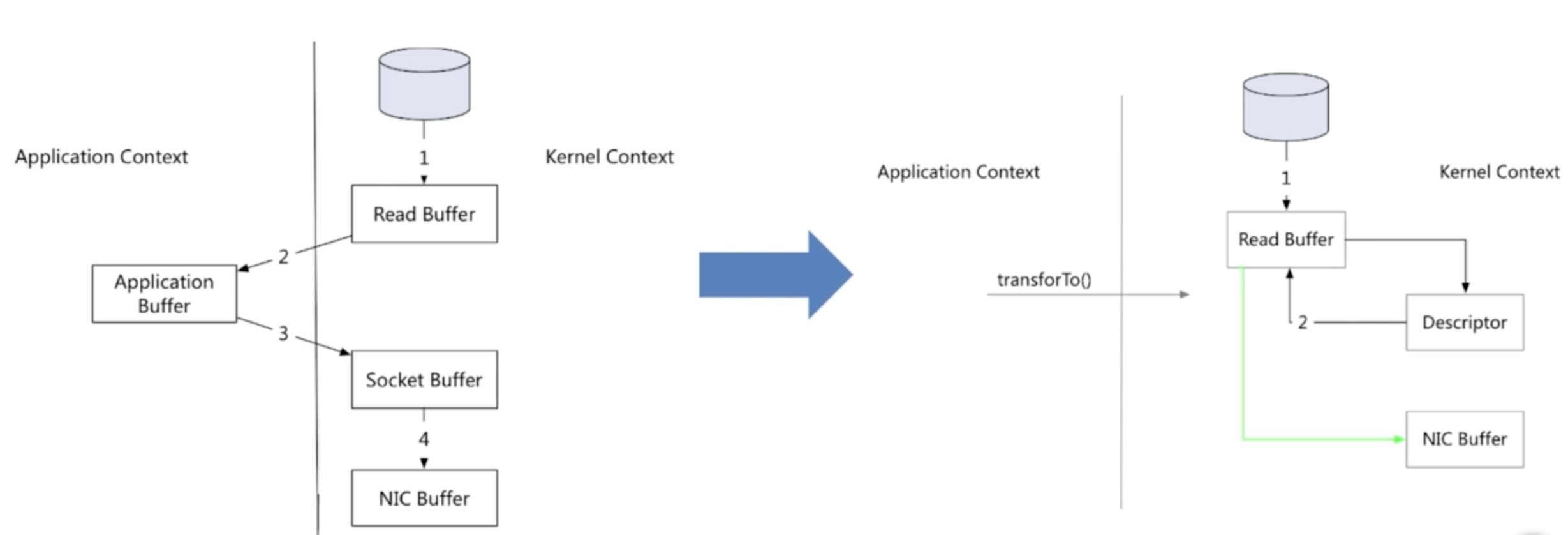
零拷贝:内核和用户空间的交互次数为0
kafka-进阶 MQ传统应用场景–异步处理 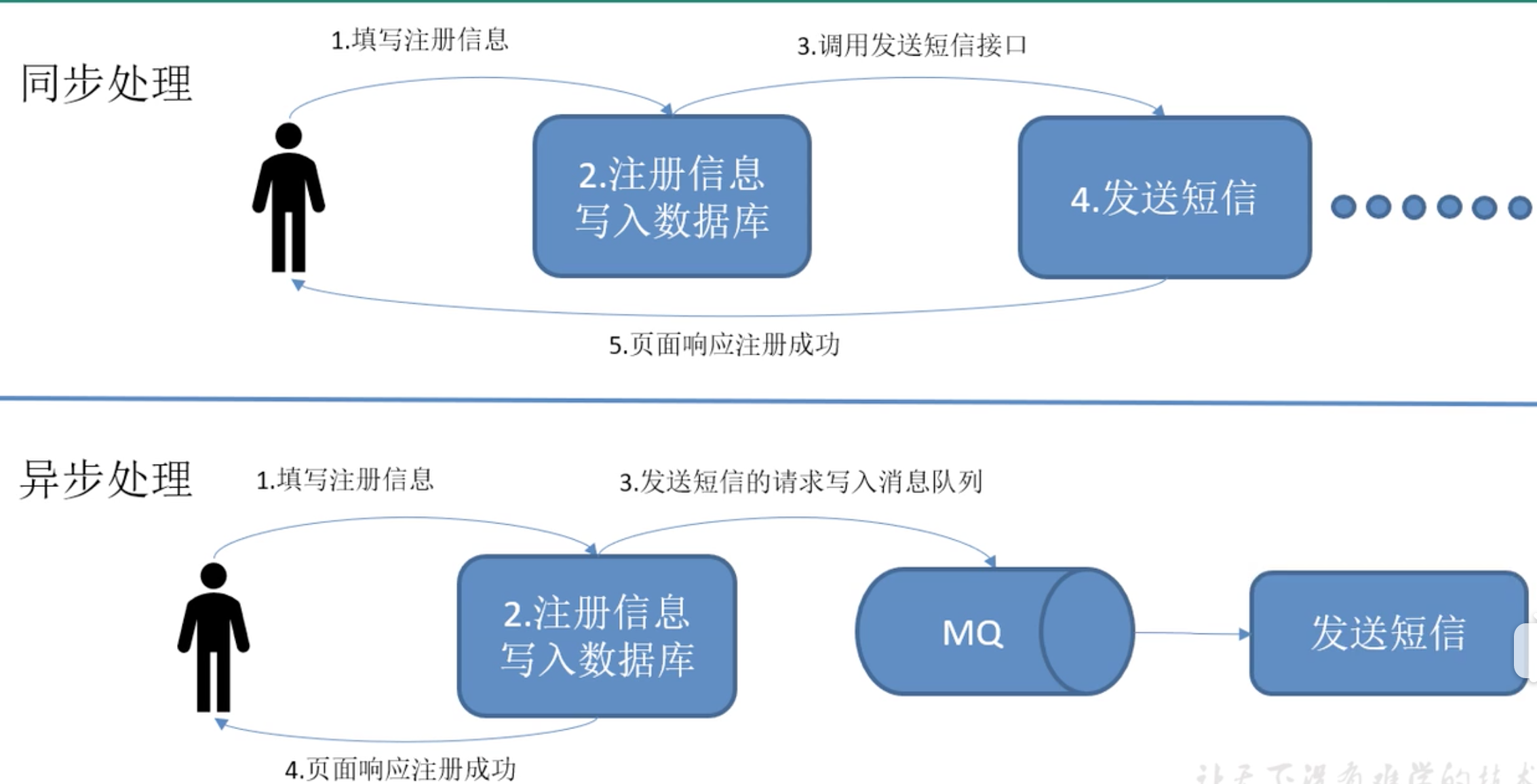
为什么要使用MQ?
解耦:
冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风
扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。 如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列 能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所 以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且 能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性)
缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致 的情况。
异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户 把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要 的时候再去处理它们。
MQ的2种模式 (1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息, 而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者 接收处理,即使有多个消息监听者也是如此。
(2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即 使当前订阅者不可用,处于离线状态。
什么是 Kafka 在流式计算中,Kafka 一般用来缓存数据,Storm 通过消费 Kafka 的数据进行计算。
Kafka 是一个分布式消息队列。Kafka 对消息保存时根据 Topic 进行归类,发送消息
无论是 kafka 集群,还是 consumer 都依赖于 zookeeper 集群保存一些 meta 信息,
Kafka架构 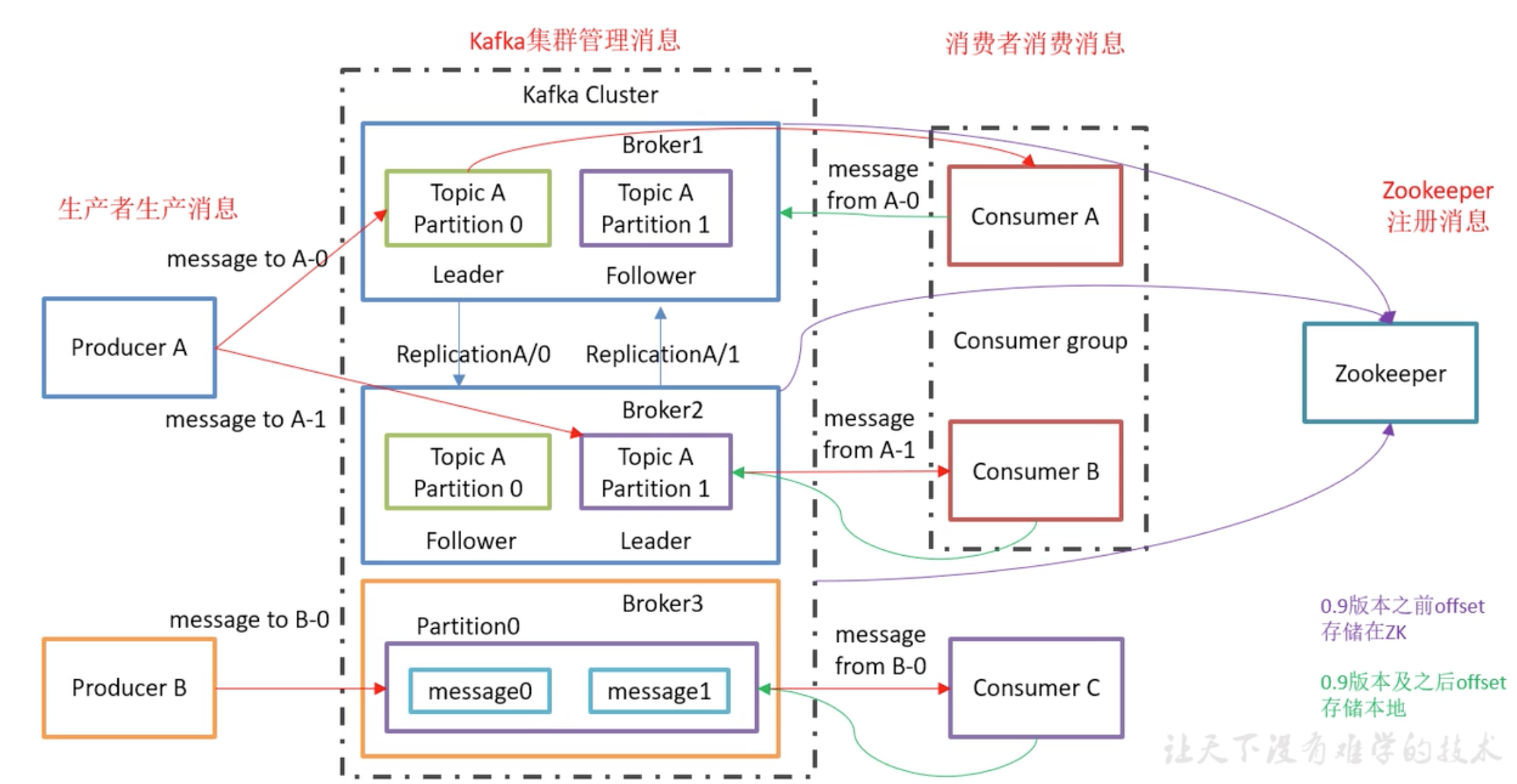
patition:提供topic的负载均衡,每个分区都在其他节点有副本。
一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。
patition0和patition1的内容是不一样的。partition 中的每条消息
producer采用轮询方式向kafka broker 发消息。
某一个分区 只能被同一个消费者组里的某一个消费者 消费。
组的作用是提高消费并发的,提高消费能力。
Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查
Kafka安装 安装配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 kafka_2.12-2.3.0.tgz # config/server.properties # 一些参数介绍 # 文件暂存的时间 log.retention.hours=168 # zookeeper地址,集群时用逗号分隔 zookeeper.connect=localhost:2181 # 进入kafka目录 mkdir logs # 修改以下内容 # 存的就是数据 log.dirs=/home/machine/apps/kafka_2.12-2.3.0/logs # 环境变量可以配一下 # xsync是一个分发脚本,适合集群搭建的时候使用 # xcall.sh jps 查看集群
启动
1 2 3 4 5 6 7 8 # 先启动zookeeper zkServer.sh start # 启动阻塞进程 bin/kafka-server-start.sh config/server.properties # 启动守护进行 bin/kafka-server-start.sh -daemon config/server.properties jps # 发现多了个kafka





