第15章 应用限流思路
限流就是通过对并发访问/请求进行限速或一个时间窗口内的请求进行限速,从而达到保护系统的目的。一般系统可以通过压测来预估能处理的峰值,一旦达到设定的峰值阀值,则可以拒绝服务(定向错误页或告知资源没有了)、排队或等待(例如:秒杀、评论、下单)、降级(返回默认数据)。
为什么需要限流
应用限流:
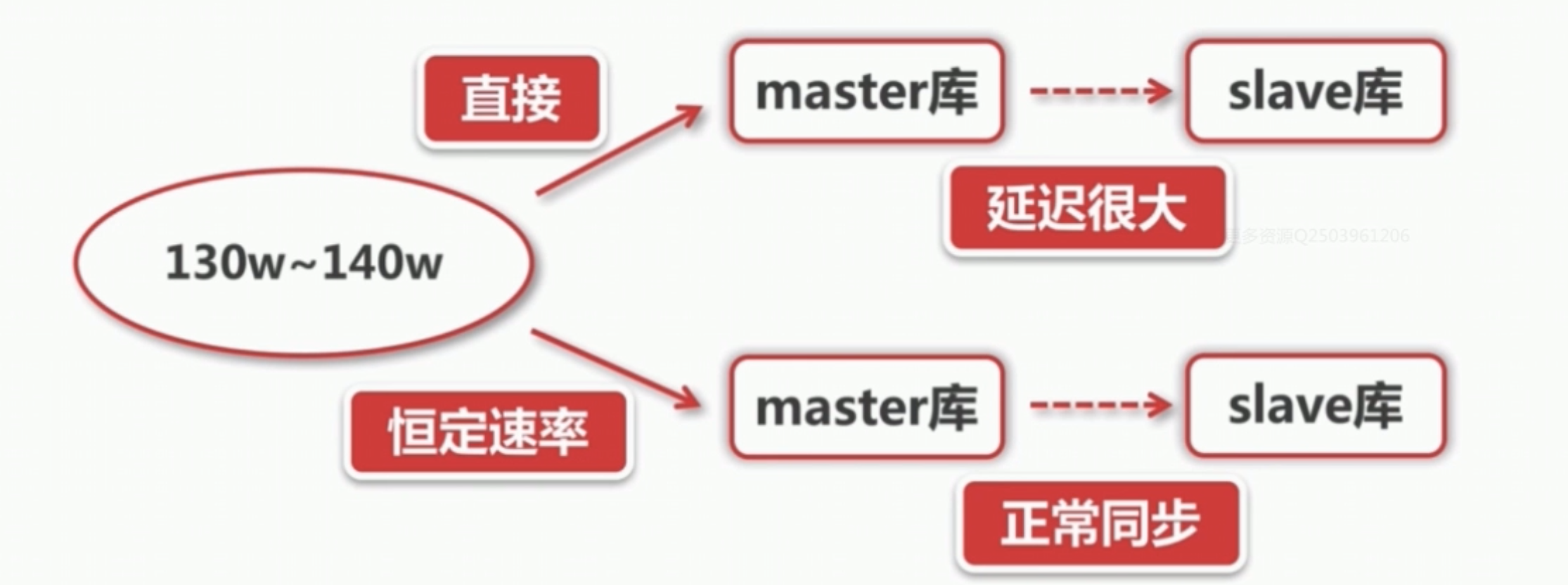
假设有130W到140W的数据插入到数据库中,如果没有做限流,数据库的主库会突然接收到130w的插入操作
首先是网络上的开销,很可能直接把带宽占满,导致其他请求无法正常传输和处理,其次会是数据库的负载突然增高,导致无法处理某些数据库的操作,也有可能数据库没有足够的连接导致某些数据库插入查询失败;
还有一点就是现在数据库都做了主从设计,主数据库的数据还要同步给从库,这时瞬间插入了大量的数据,会带来从库和主库的延迟特别大,这时从库查询不准确的概率也会跟着提升。
如果我们放慢插入数据库的速度,这时插入数据库主库的速率会很正常,同步到从库也很正常。网络消耗也可以接收不会影响其他服务。
应用限流算法
- 计数器法
- 滑动窗口
- 漏桶算法
- 令牌桶算法
1、计数器法
使用计数器来进行限流,主要用来限制一定时间内的总并发数,比如数据库连接池、线程池、秒杀的并发数;计数器限流只要一定时间内的总请求数超过设定的阀值则进行限流,是一种简单粗暴的总数量限流,而不是平均速率限流。
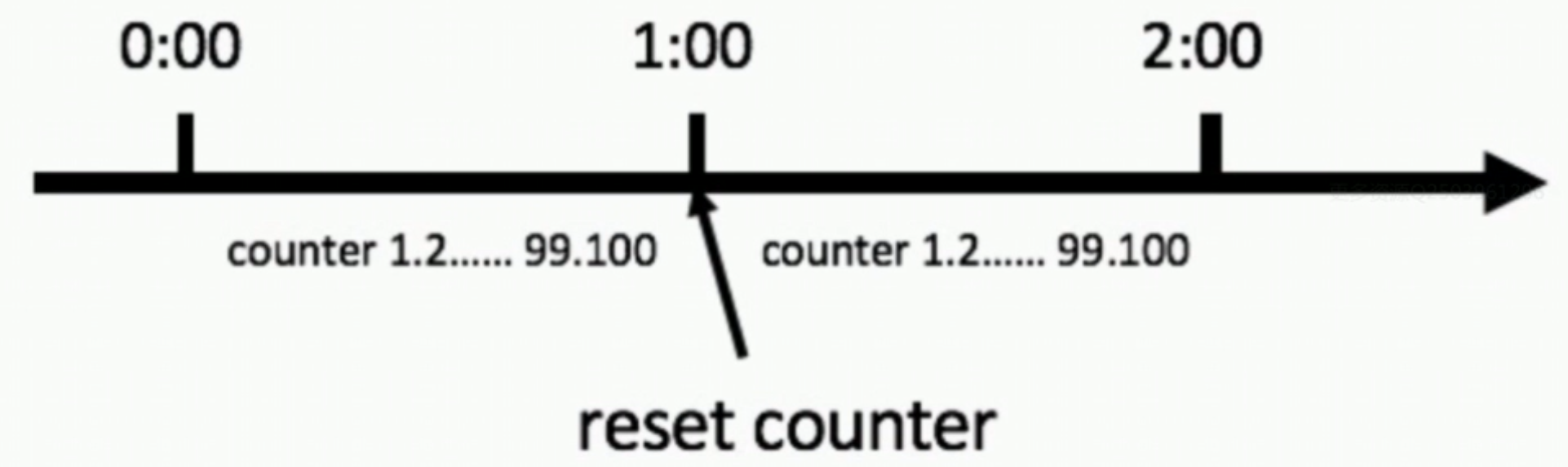
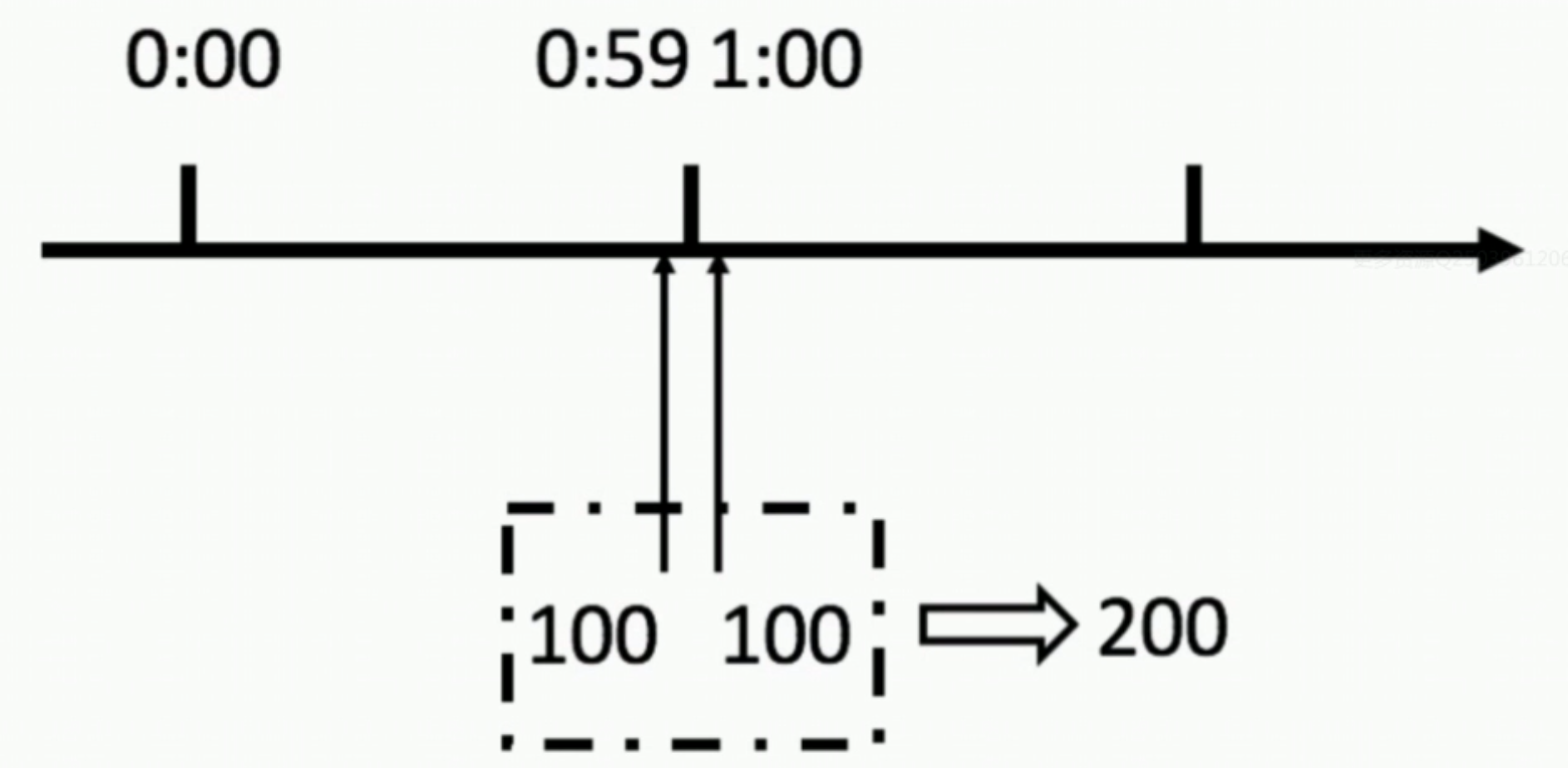
这个方法有一个致命问题:临界问题——当遇到恶意请求,在0:59时,瞬间请求100次,并且在1:00请求100次,那么这个用户在1秒内请求了200次(59s时请求100次,然后60s时重置计数,又立马请求100次,所以1秒内请求了200次,超过了1s请求100次的阀值),用户可以在重置节点突发请求,而瞬间超过我们设置的速率限制,用户可能通过算法漏洞击垮我们的应用。
2、滑动窗口算法
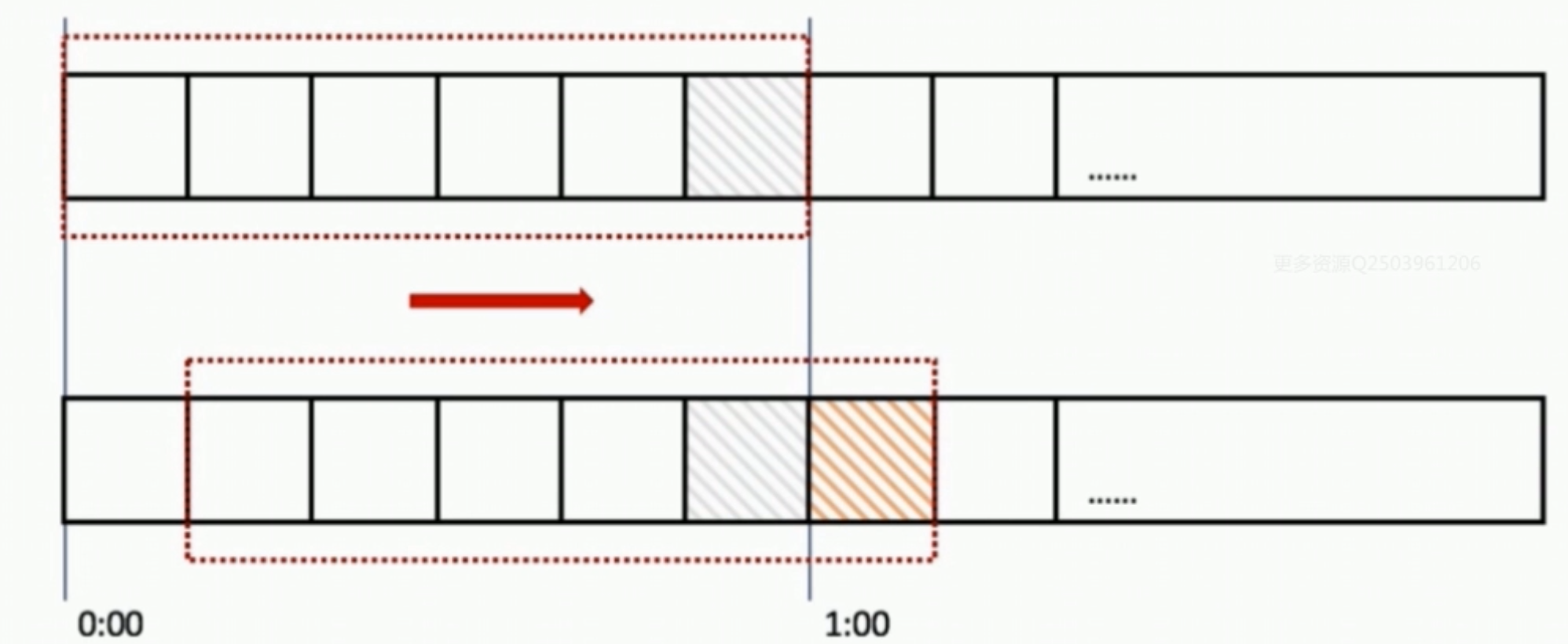
在上图中,整个红色矩形框是一个时间窗口,一个时间窗口就是1分钟,然后我们将时间窗口进行划分。
如上图我们把滑动窗口划分为6格,所以每一格代表10秒,每超过10秒,我们的时间窗口就会向右滑动一格,每一格都有自己独立的计数器。例如:一个请求在0:35到达,那么0:30到0:39的计数器会+1。
那么滑动窗口是怎么解决临界点的问题呢?如上图,0:59到达的100个请求会在灰色区域格子中,而1:00到达的请求会在红色格子中,窗口会向右滑动一格,那么此时间窗口内的总请求数共200个,超过了限定的100,所以此时能够检测出来触发了限流(计数器法利用临界点1秒请求200次会检测不出来)。
回头看看计数器算法,会发现,其实计数器算法就是窗口滑动算法,只不过计数器算法没有对时间窗口进行划分,所以是一格。
由此可见,当滑动窗口的格子划分越多,限流的统计就会越精确。
3、漏桶算法(Leaky Bucket)
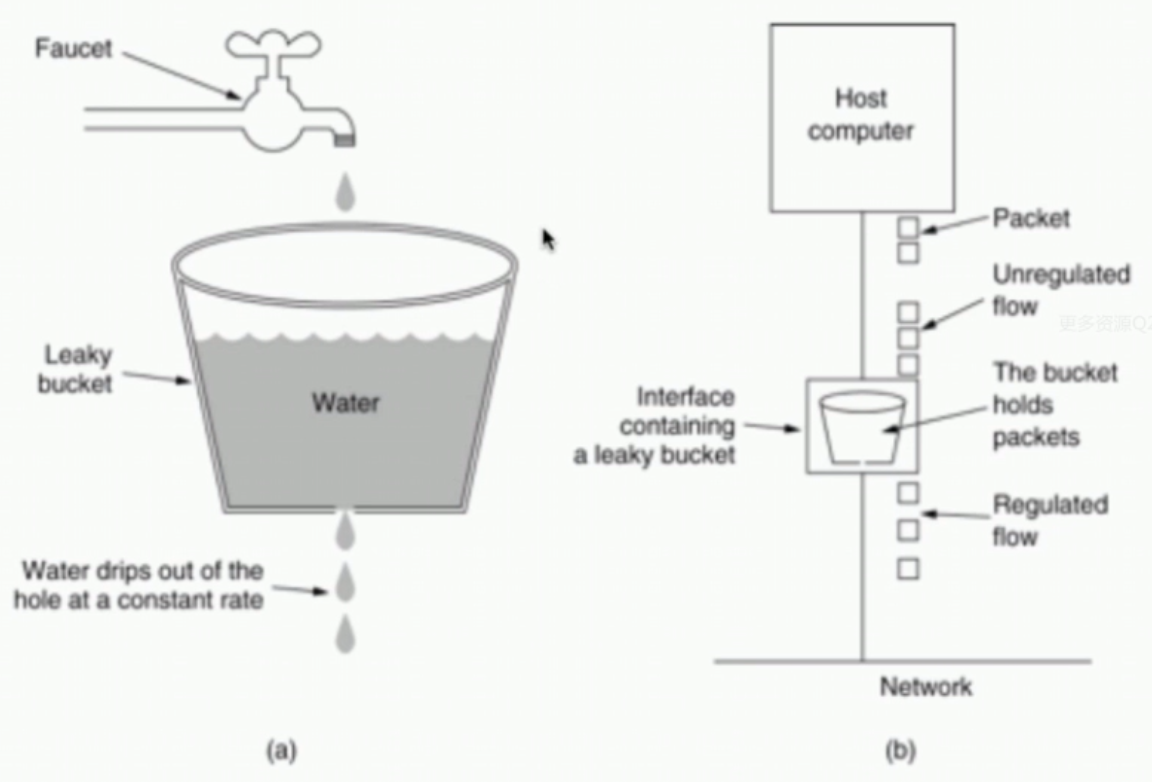
这个算法很简单。首先,我们有一个固定容量的桶,有水进来,也有水出去。对于流进来的水,我们无法预计共有多少水流进来,也无法预计流水速度,但对于流出去的水来说,这个桶可以固定水流的速率,而且当桶满的时候,多余的水会溢出来。
4、令牌桶算法(Token Bucket)
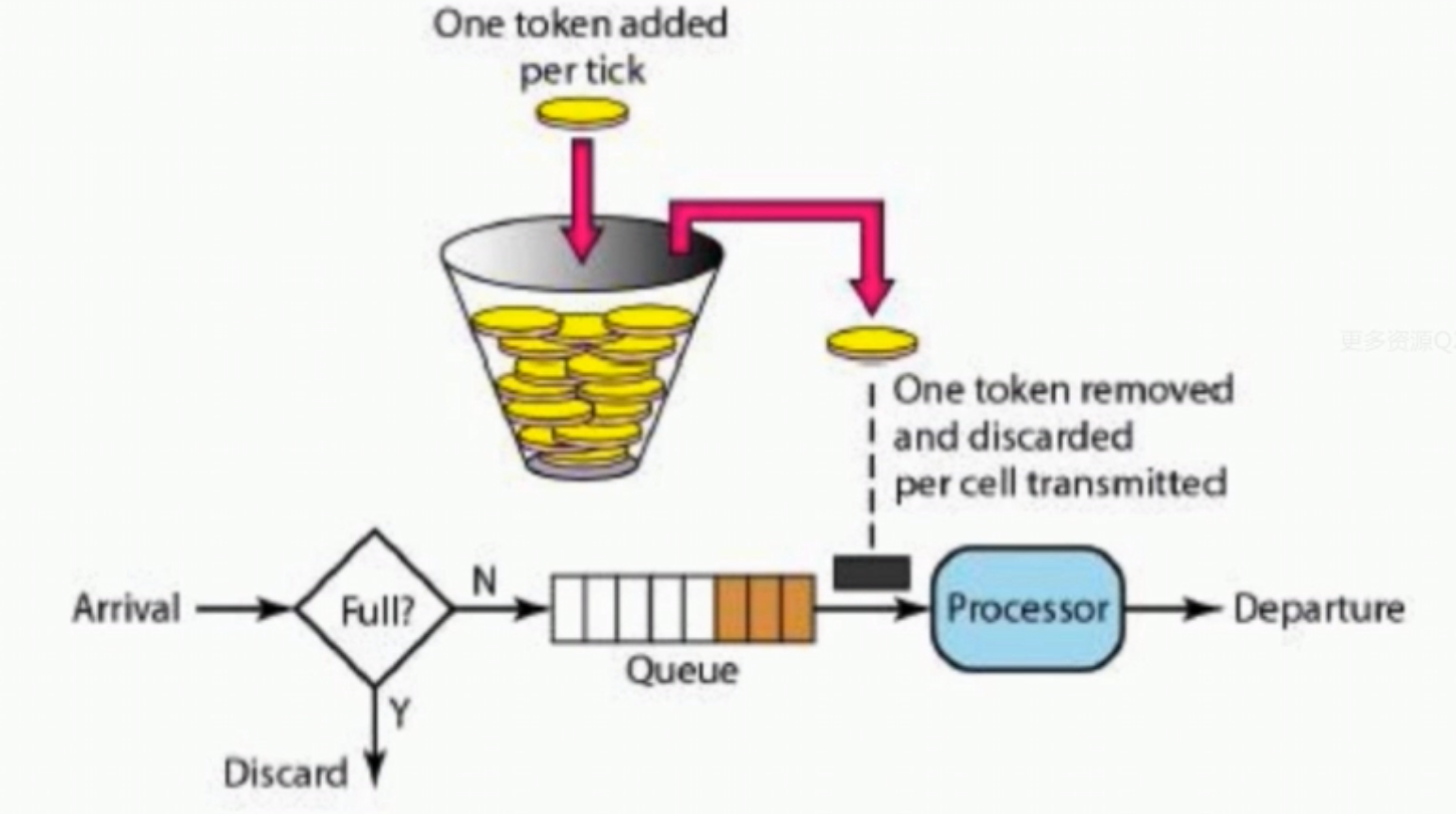
从上图中可以看出,令牌算法有点复杂,桶里存放着令牌token。桶一开始是空的,token以固定的速率r往桶里面填充,直到达到桶的容量,多余的token会
被丢弃。每当一个请求过来时,就会尝试着移除一个token,如果没有token,请求无法通过(解决了临界问题,1s内最高并发100个)。
算法对比
计数器法 VS 滑动窗口
计数器法是滑动窗口的低精度实现
滑动窗口比计数器法需要更多存储空间(每一格都有自己独立的计数器)
漏桶算法 VS 令牌桶算法
- 允许一定程度的突发(漏桶是匀速的),因为默认取令牌不消耗时间,所以对用户更友好,被业界采用较多
- 令牌桶就是匀速,且没有临界问题
第16章 服务降级与服务熔断思路
概念理解
服务降级:
服务压力剧增的时候根据当前的业务情况及流量对一些服务和页面有策略的降级,以此缓解服务器的压力,以保证核心任务的进行。
同时保证部分甚至大部分任务客户能得到正确的响应。也就是当前的请求处理不了了或者出错了,给一个默认的返回。
服务熔断:
在股票市场,熔断这个词大家都不陌生,是指当股指波幅达到某个点后,交易所为控制风险采取的暂停交易措施。相应的,服务熔断一般是指软件系统中,由于某些原因使得服务出现了过载现象,为防止造成整个系统故障,从而采用的一种保护措施,所以很多地方把熔断亦称为过载保护。
降级分类
降级按照是否自动化可分为:自动开关降级和人工开关降级。
降级按照功能可分为:读服务降级、写服务降级。
降级按照处于的系统层次可分为:多级降级。
自动降级分类
(1)超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况
(2)失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
(3)故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)
(4)限流降级
当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)。
服务熔断和服务降级比较:
类似性:
- 目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
- 最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
- 粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
- 自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;
而两者的区别也是明显的:
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)
- 实现方式不太一样
服务降级要考虑的问题:
核心和非核心服务
是否支持降级,降级策略
业务放通的场景,策略
Hystrix
Hystrix,该库旨在通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix具备拥有回退机制和断路器功能的线程和信号隔离,请求缓存和请求打包(request collapsing,即自动批处理,译者注),以及监控和配置等功能。


???






