第9章 服务容错
服务容错和Hystrix
问题引出:
雪崩效应:A —> B —> C ,B调用C不可用,B一直重试,A调用B也不可用了,这样,资源耗尽,整个系统不可用
Spring Cloud Hystrix
- 防雪崩利器
- 服务降级
- 场景:“服务开小差,请稍后重试”
- (在高流量场景下)优先核心服务,非核心服务不可用或弱可用
- 通过HystrixCommand注解指定
- fallbackMethod中具体实现降级逻辑
- 服务熔断
- 依赖隔离
- 监控(Hystrix Dashboard)
触发降级
pom
1 | <dependency> |
启动类
1 | //代替以下3个 |
触发降级
1 | package com.mxx.order.controller; |
超时设置
超过指定时间还没有访问成功,就降级处理
1 | (fallbackMethod = "fallback", |
依赖隔离??
- 线程池隔离
- Hystrix自动实现了依赖隔离
服务熔断
探讨断路器模式
1 | Circuit Breaker:断路器(电流过大时会烧坏保险丝,保护电路) |
断路器状态图:
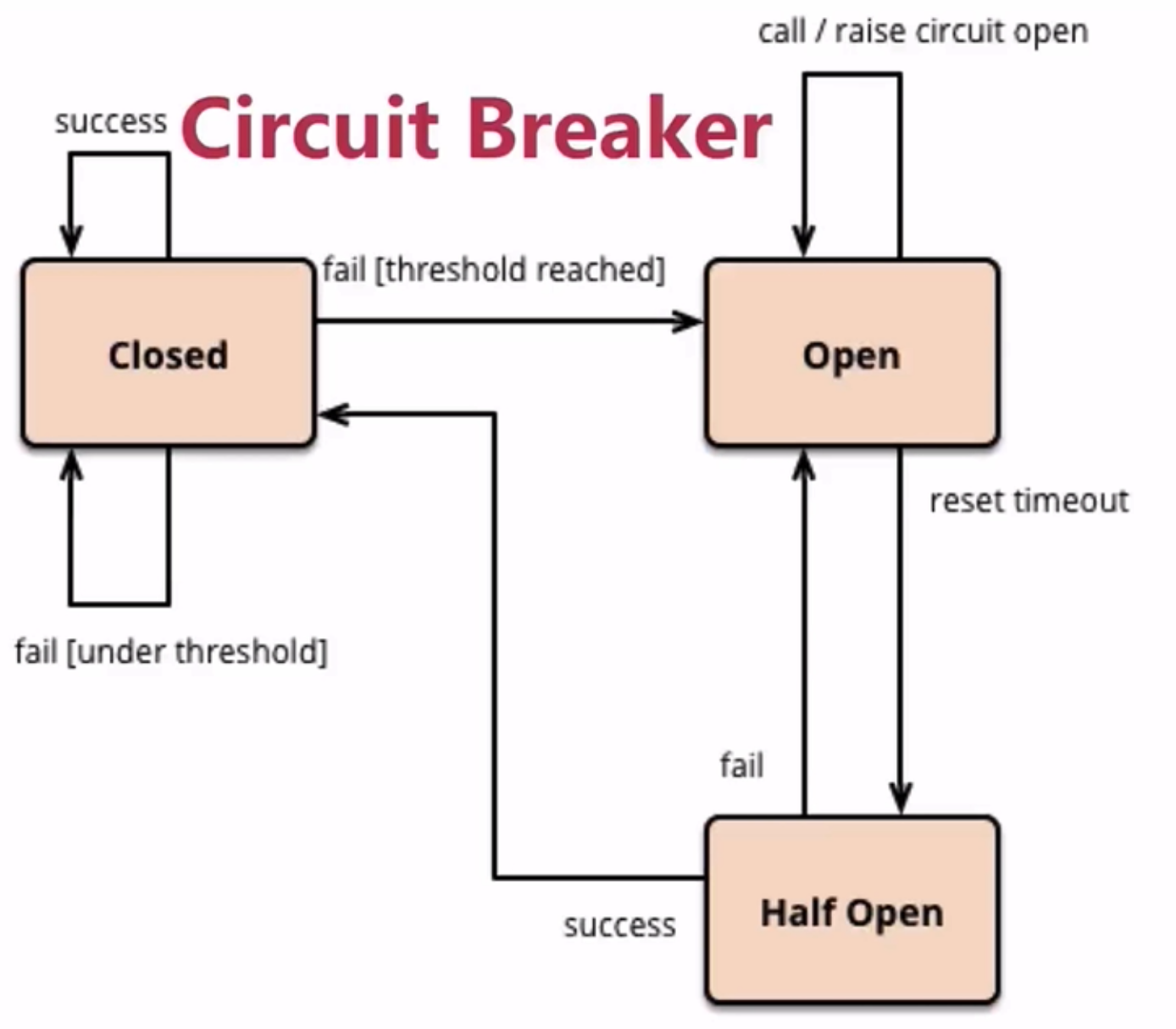
解释:
- 熔断器开始处于close状态,当调用失败次数累计到了阈值(比例),就会启动熔断机制(open),此时对服务都返回错误,但设置了个时钟,到了时钟后进入半熔断状态(Half Open),允许定量服务请求。
- 在Half Open下,若服务都调用成功(或者满足成功比例),则认为恢复了,就会关闭(closed),否则又回到open状态
关键参数
1 | circuitBreaker.enabled //开启熔断服务 |
解释:
当调用失败次数达到 “错误百分比条件” ,断路器从“closed”进入“half open”。
当断路器“open”后,Hysticx会启动“休眠时间窗口”,在这个时间内,降级逻辑(fallbackMethod)成为临时主逻辑,当时间到期,断路器进入“half open”,释放一次请求到原来的逻辑上,若此次请求返回正常,则断路器“close” ,主逻辑恢复。否则,断路器“open”,“休眠时间窗口”重置计时。
操作:
1 | (commandProperties = { |
改为 使用yml配置项:
1 | hystrix: |
hystrix-dashboard
pom
1 | <dependency> |
yml
1 | management: |
启动类
1 | @EnableHystrixDashboard |
访问:http://localhost:8081/hystrix
dashboard:
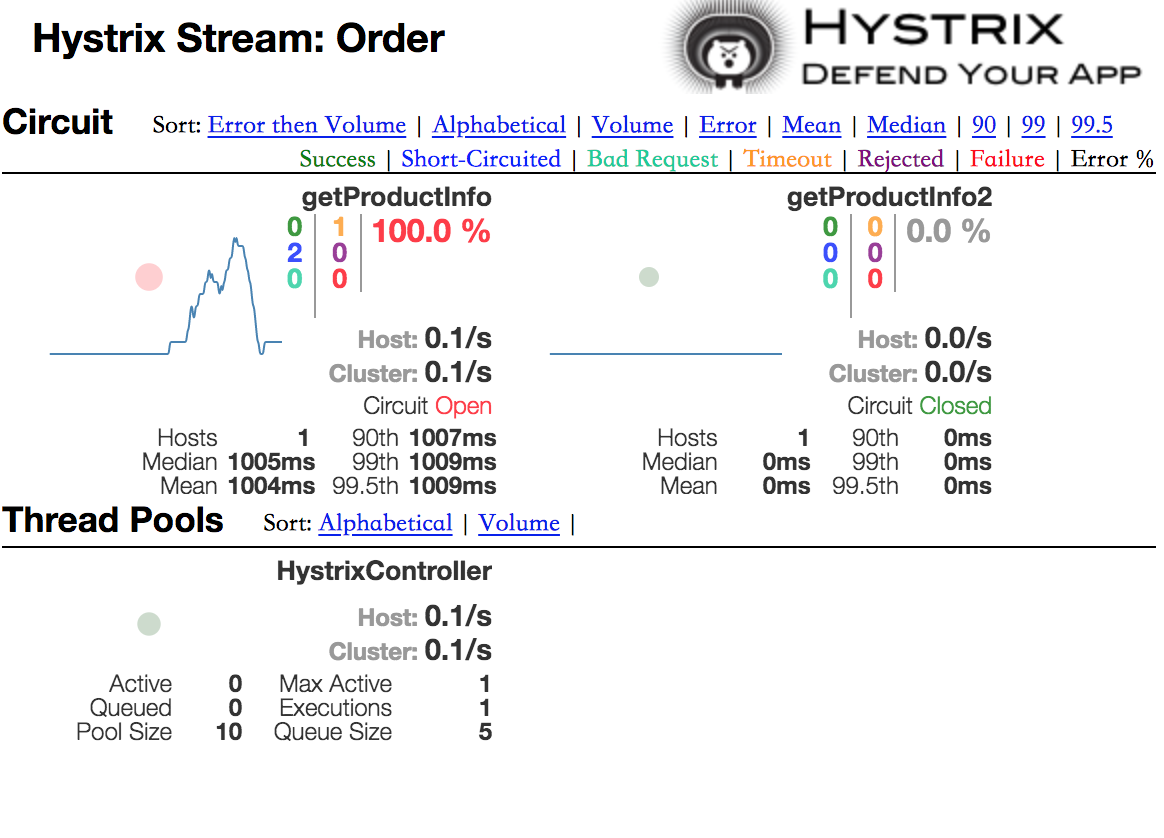
再看熔断器状态:
closed –> open:当请求数达到“断路器最小请求数”,且失败率大于“错误百分比条件”
closed –> half open:当调用失败次数达到 “错误百分比条件”
open –> half open:当断路器“open”后,Hysticx会启动“休眠时间窗口”,在这个时间内,降级逻辑(fallbackMethod)成为临时主逻辑,当时间到期,断路器进入“half open”
half open –> closed:进入“half open”后,释放一次请求到原来的逻辑上,若此次请求返回正常,则断路器“close” ,主逻辑恢复
half open –> open:进入“half open”后,释放一次请求到原来的逻辑上,若此次请求返回失败,则断路器“open” ,“休眠时间窗口”重置计时。
Zuul:超时配置
问题引出:通过zuul第一次访问服务容易超时
解释:由于懒加载配置,第一次访问时会加载很多类,导致超过默认时间
如何修改默认超时时间?zuul使用的是hystrix的超时组件
1 | hystrix: |
第10章 服务跟踪
实操:Sleuth+Zipkin
链路监控
Spring Cloud Sleuth
xml1
2
3
4
5<!-- order 和 product 都要包含-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>可视化工具:zipkin
- https://zipkin.io/
- 使用docker:docker run -d -p 9411:9411 openzipkin/zipkin
xml1
2
3
4
5<!-- 包含以上两个依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>- 配置
yaml1
2
3
4
5
6
7
8
9
10
11
12
13# order
spring:
zipkin:
base-url: 10.211.55.6:9411
sender:
type: web
sleuth:
sampler:
probability: 1 # 抽样比100%
# order | product
logging:
level:
org.springframework.cloud.openfeign: debug- ui展示

可查看某个调用链的请求时间都花在哪一步了。
理论:分布式追踪系统
分布式追踪系统
核心步骤
- 数据采集
- 数据存储
- 查询展示
说明
- 不同系统api不兼容,改动起来工作量很大
- OpenTracing:解决不同分布式系统api不兼容问题,是一种标准
- Annotation:事件类型…
- Zipkin:遵循OpenTracing的产品,Twitter开源
zipkin原理图
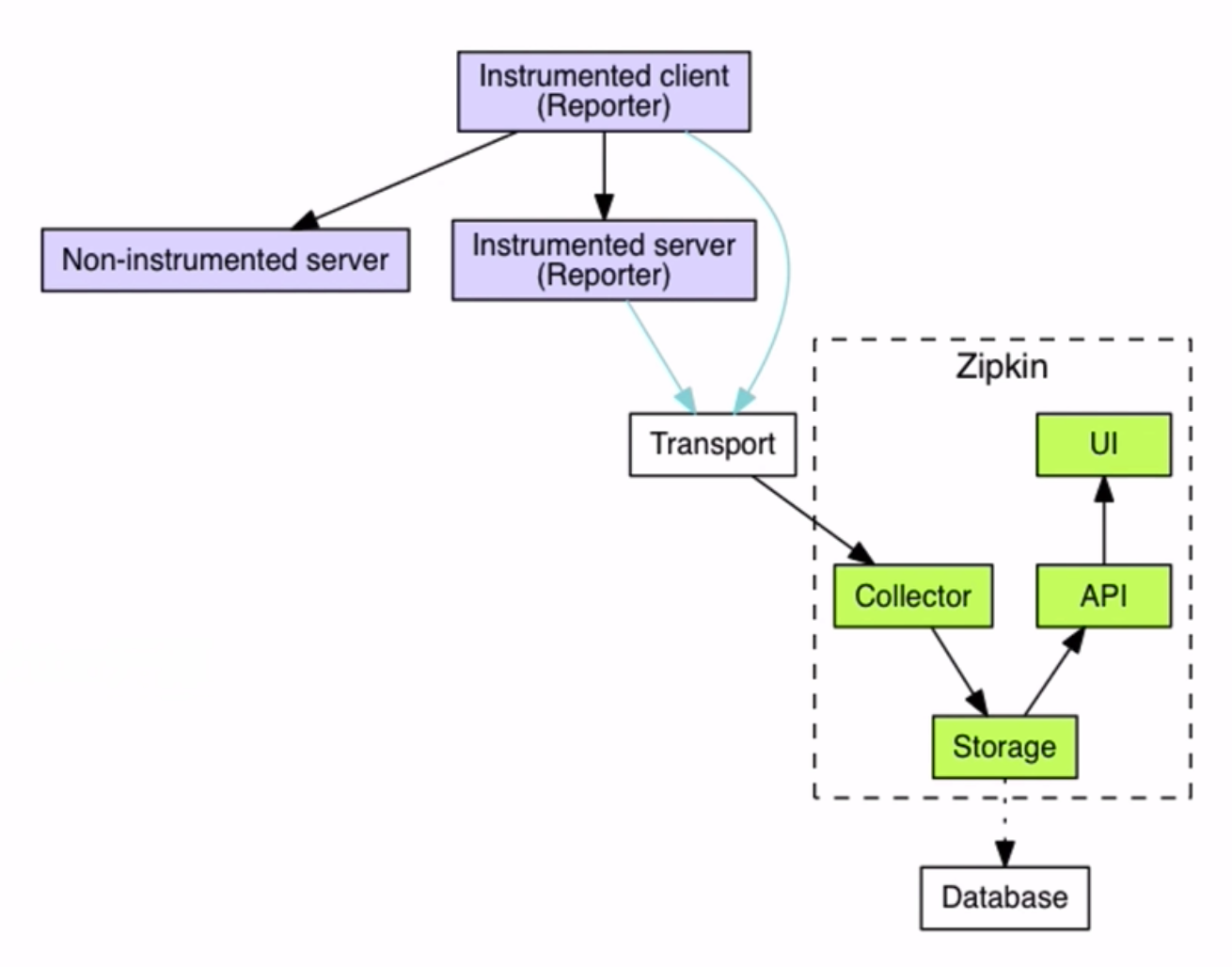
zipkin关键概念
- traceId
- spanId
- parentId
第11章 容器部署
Eureka使用Docker部署
Dockerfile
1 | FROM hub.c.163.com/library/java:8-alpine |
运行$ docker build -t myspringcloud/eureka .制作镜像
rancher
开源企业级全栈化容器部署及管理平台[更方便地管理Docker]
安装rancher
docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher:stable登录后主界面
课程推荐:[Docker+Kubernetes微服务容器化实践]
方法总结:rancher+docker+网易云远程仓库 实现分布式部署





