参考:
- imooc 认识Hadoop–基础篇
- 笔记 Hadoop大数据平台架构与实践–基础篇
- 我的代码:
简介
大数据时代已经到来,越来越多的行业面临着大量数据需要存储以及分析的挑战。Hadoop,作为一个开源的分布式并行处理平台,以其高扩展、高效率、高可靠等优点,得到越来越广泛的应用。本课旨在培养学员理解Hadoop的架构设计以及掌握Hadoop的运用能力。
第1章 初识Hadoop
1-1 Hadoop大数据平台架构与实践
学习目标:
掌握大数据存储与处理技术的原理(理论)
掌握Hadoop的使用和开发能力
学习建议:
《Hadoop技术详解》《Hadoop权威指南》
Linux命令、Java编程基础
1.大数据的相关概念
2.Hadoop的架构和运行机制
3.实战:Hadoop的安装和配置
4.实战:Hadoop开发
1-2 Hadoop的前世今生
系统瓶颈:存储容量 读写速率 运行效率
google 提出三大关键技术mapreduce Bigtable GFS
革命性变化:
1、降低成本,普通PC集群;
2、硬件故障是常态,利用软件保证高可靠性;
3、简化并行计算,无须同步和数据交换
hadoop:是模拟谷歌的分布式的开源实现,其作用是降低成本,可容错,高效计算
容错性:硬件故障是常态,通过软件来保证可靠性
1-3 Hadoop的功能与优势
Hadoop=分布式存储+分布式计算
包括两个核心组成:
HDFS:分布式文件系统,存储海量的数据
MapReduce:并行处理框架,实现任务分解和调度。
优势:高扩展、低成本
Hadoop可以用来搭建大型数据仓库,PB级数据的存储、处理、分析、统计等业务
1-4 Hadoop生态系统及版本
Hadoop不仅包括HDFS和MapReduce,还包括一次额开源工具。比如:
HIVE,本意是小蜜蜂,轻盈。
HBASE,存储结构化数据的分布式数据库。区别于HDFS的一点是,HABASE提供数据的随机读写和实时访问,实现对表数据的读写功能。
zookeeper,动物管理员。 监控Hadoop集群里面每个节点的状态,管理整个集群的配置,维护节点之家数据的(一次?依次)性
hive使sql转成一个hadoop任务去执行,降低hadoop的门槛。
hive(sql语句转换工具) habse(结构型数据,随机写入和实时读取) zookeeper(监控个节点使用、配置)。
habase存储结构化数据的分布式数据库,放弃事务特性,追求更高的扩展。habase提供数据的随机读写和实时访问,实现对表数据的读写功能。
zookeeper监控hadoop每个节点的状态,管理集群配置,维护节点间数据的一致性。
zookeeper的作用:
1)监控hadoop每个节点的状态
2)管理整个集群的配置
3)维护节点间数据的一致性
hadoop生态系统:
1.hdfs
2.mapreduce
3.相关开源工具:
(1)hive:将简单的sql语句转化为hadoop任务,降低使用hadoop的门槛
(2)HBASE:区别于传统数据库:存储结构化数据的分布式数据库,放弃事务特性,追求更高的扩展,它提供数据的随机读写和实时访问,实现对表数据的读写功能
(3)zookeeper:监控Hadoop集群里的每个节点的状态,管理整个集群的配置,维护数据节点之间的一致性
Hadoop版本最高2.6,初学者建议1.2(ver1.2-稳定)
第2章 Hadoop安装
2-4 安装小结
修改4个配置文件
(a) 修改hadoop-env.sh,设置JAVA_HOME
(b) 修改core-site.xml,设置hadoop.tmp.dir, dfs.name.dir, fs.default.name
(c) 修改mapred-site.xml,设置mapred.job.tracker
(d) 修改hdfs-site.xml,设置dfs.data.dir
hadoop安装步骤:
1、安装JDK:apt-get install openjdk-7-jdk;
2、设置环境变量:JAVA_HOME、JRE_HOME、CLASSPATH、PATH(在/etc/profile)
3、下载hadoop安装包并解压到指定目录下;
4、设置环境变量:HADOOP_HOME、PATH(在/etc/profile)
5、修改相关配置文件$HADOOP_HOME/conf:
1)修改hadoop-env.sh,设置JAVA_HOME;
2)修改core-site.xml,设置hadoop.tmp.dir、dfs.name.dir、fs.default.name;
3)修改mapred-site.xml,设置mapred.job.tracker;
4)修改hdfs-site.xml,设置dfs.data.dir;
6、格式化:hadoop namenode -format;
7、启动:start-all.sh
8、检查:jps
第3章 Hadoop的核心-HDFS简介
3-1 HDFS基本概念
HDFS的文件被分成快进行存储
HDFS块的默认大小64MB
块是文件村春处理的逻辑单元
nameNode 是管理节点,用来读取元数据的
DataNode是数据节点,用来存储数据的
HDFS——文件系统
MapReduce——并行计算框架
namenode是管理节点,存放文件元数据,元数据包括两部分:
- 文件与数据块的映射表
- 数据块与数据节点的映射表

3-2 数据管理策略
hdf数据管理策略:
- hdfs是采用master-slave的模式关管理文件,即一个master(namenade:保存datanode的一些基本信息和元数据)和多个slave(datanode:真正的存贮单元,里面存储了真实数据)
- hdfs默认保存三份文件,有两份保存在同一台机器上,另外一份(备份文件)保存到另外一台机器上,确保当一台机器挂了时能保存数据的存在
- namenade也有一个备用节点:Secondary NameNode,当namenode挂了时secondaryNameNode就变为nameNode的角色进行管理数据
- datandoe会采用心跳的方式时不时的想namenode报告自己的基本信息,比如网络是否正常,运行是否正确常。
3-3 HDFS中文件的读写操作

客户端发出读请求,namenode根据元数据返回给客户端,下载需要的block并组装
HDFS读取文件的流程:
(1)客户端向namenode发起读文件请求,把文件名,路径告诉namenode;
(2)namenode查询元数据,并把数据库返回客户端;
(3)此时客户端就明白文件包含哪些块,这些块在哪些datanode中可以找到;

HDFS写数据:首先将文件拆分为默认大小64M的块。通知NameNode,找到并返回可用的datanode信息,客户端写入一个后,其他的进行流水线复制。最后更新元数据。
HDFS写文件流程:
(1)客户端把文件拆分成固定大小64M的块,并通知namenode;
(2)namenode找到可用的datanode返回给客户端;
(3)客户端根据返回的datanode,对块进行写入
(4)通过流水线管道流水线复制
(5)更新元数据。告诉namenode已经完成了创建心的数据块。保证了namenode中的元数据都是最新的状态。
3-4 HDFS特点
1)数据冗余,硬件容错;
2)流式的数据访问,写一次,读多次。数据没办法修改,如果要修改只能把之前的数据删除,然后重新写入一份;
3)适合存储大文件,这是设计之初就这么考虑的,如果是大量的小文件的话,不适合,因为一个小文件也要存储元数据,此时NameNode的压力会非常大。
4)适合数据的批量读写,吞吐量高,不适合做交互式应用,低延迟很难满足;
5)支持顺序读写,不支持此多用户并发写相同文件;
3-5 HDFS使用
hadoop的几个常用命令来演示如何在hadoop中创建一个目录,然后上传一个文件,然后再下载一个文件。
大致都是:
hadoop fs -put filea.dat input/
或者是get命令下载文件
或者是cat命令查看文件内容
或者是hdfsadmin命令来查看整个系统的一些统计信息。
第4章 Hadoop的核心-MapReduce
4-1 MapReduce的原理
所谓Map就是要将任务拆分成很多份,这里给了一个例子,有1000副牌,少了一张,然后要找出到底是少了哪一章。

然后又给了一个从日志中统计出访问此处最多的ip的例子,也都是类似的,先把日志分块,然后由不同的任务分别统计,然后再把他们的结果拿来合并,也就是Reduce了
4-2 MapReduce的运行流程
几个基本的概念:
Job&Task,比如上面的找出访问次数最多的任务就是一个Job,然后这个Job要完成的话要被分解为多个Task,放到不同的节点上去执行。Task又可以分为MapTask和ReduceTask
JobTracker,作业调度,分配任务并监控任务的执行进度,任务分配出去之后,TaskTracker每隔几秒钟要向JobTracker更新状态
TaskTracker,作业的执行
这几个概念互相之间的关系如下图:

一般来说,TaskTracker就是分配在其数据所在的DataNode上,这样可以保证运行的效率最高,毕竟读取本机的磁盘总是更快的。这也是MapReduce的一个设计思想,用移动计算来避免移动数据。

MapReduce的容错机制,
1)重复执行;也就是执行的过程中如果出错了,他会重复执行,但是重复了4次之后如果还出错,他就放弃了。
2)推测执行,用于解决那种计算速度特别慢的情况,此时会新开一个任务,然后再看这两个任务谁先执行完。
第5章 开发Hadoop应用程序
5-1~5-3 WordCount单词计数
需求:计算文件中出现每个单词的频数,输入结果按照字母顺序进行排序
1 | byte 3 |
思路:
map:切分
对每个词统计记1次
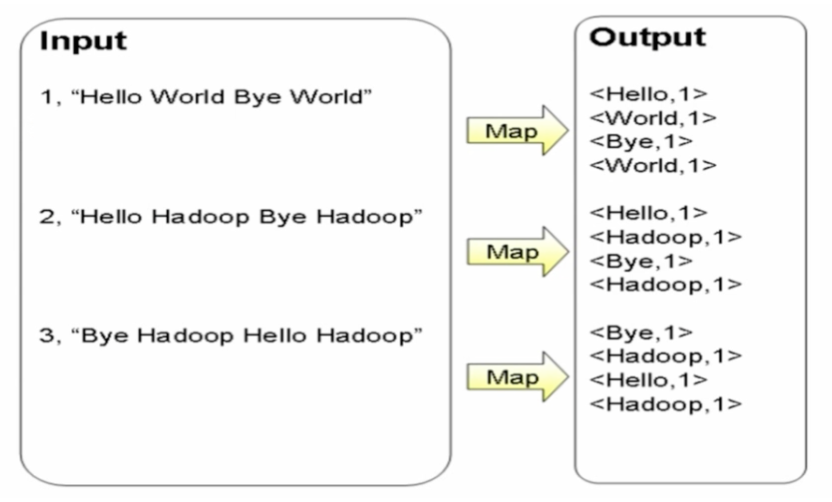
reduce:合并
相同的key放在同一个节点
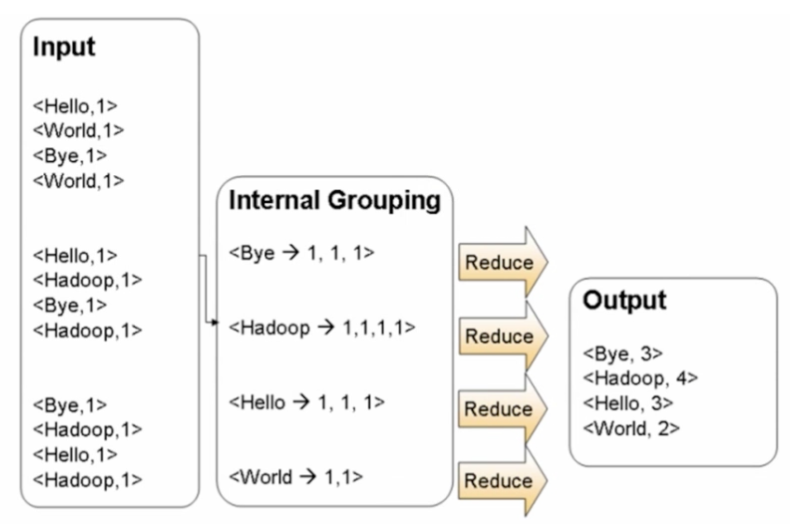
代码实现
1 | <dependency> |
1 | public class WordCount { |
输入文件如file1:
1 | hello world |
部署到hadoop上执行:
1 | - 打包成 WordCount.jar |
5-4~5-5 利用MapReduce进行排序
数据排序
思路:将数据按照大小区间分片,放到reduce进行排序
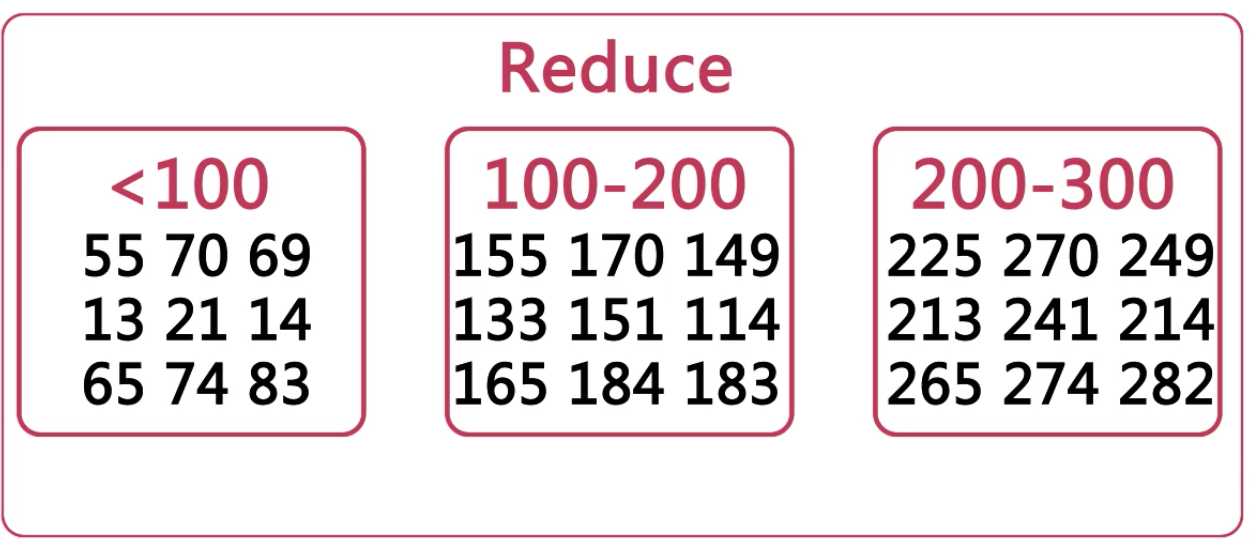
输入样例:
1 | 2 |
输出样例
1 | 1 2 |
代码:
1 | public class Sort { |
最后输出结果:
1 | 1 2 |
疑问:每个区间内部的排序是在哪里完成的?
5-6 课程总结
略






