[TOC]
YARN产生背景
1、MapReduce1.x==>MapReduce2.x
master/slave:JobTracker/TaskTracker
JobTracker:单点、压力大
仅支持mapreduce作业
2、资源利用率
所有的计算框架(Hadoop\Spark)运行在一个集群中,共享一个集群的资源,按需分配。
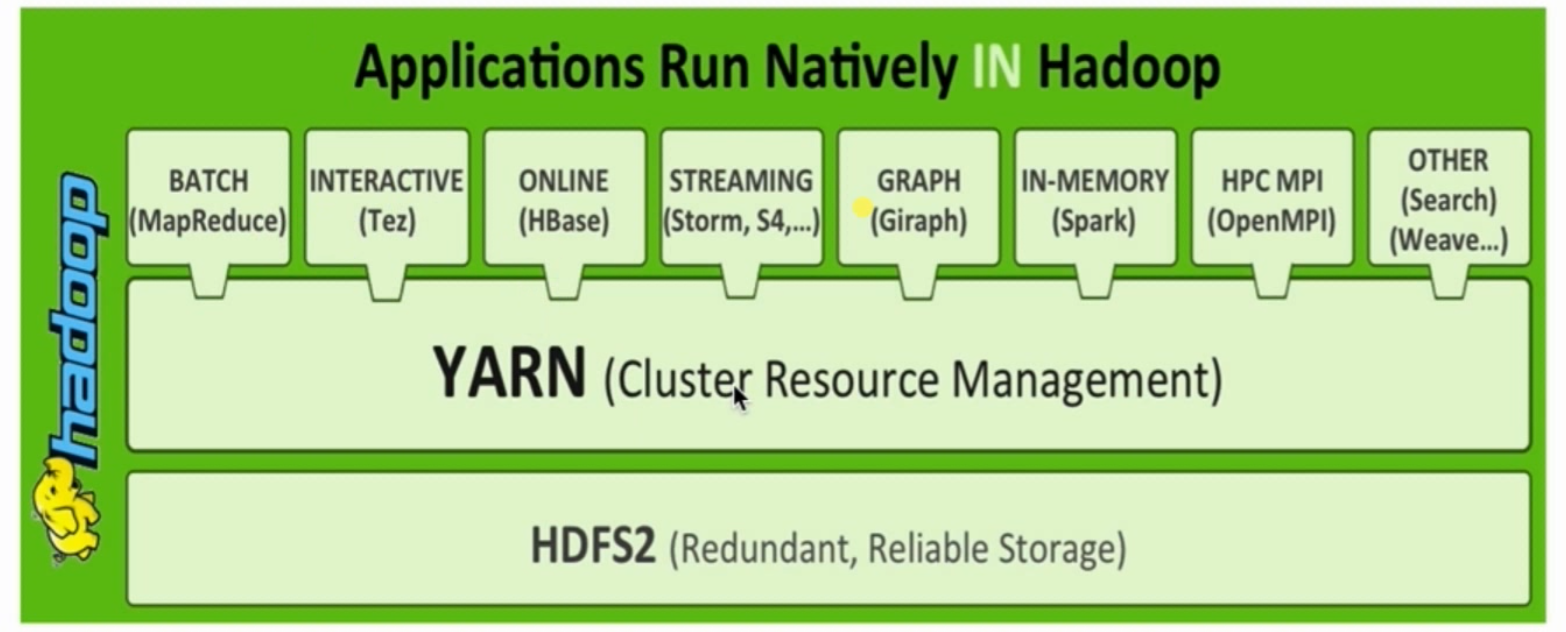
YARN概述
- Yet Another Resource Negotiator
- 通用的资源管理系统
- 为上层应用提供统一的资源管理和调度
基本思想:
以下翻译自官网:YARN架构
YARN的基本思想是将JobTracker的两个主要功能,资源管理和作业调度/监视(resource management and job scheduling/monitoring)分成单独的守护进程。
拥有一个全局ResourceManager(RM)和每个应用程序ApplicationMaster(AM)(per-application ApplicationMaster )。应用程序可以是传统意义上的Map-Reduce作业中的单个作业,也可以是作业的DAG。
ResourceManager和每个节点的从属节点NodeManager(NM)构成了数据计算框架。ResourceManager是在系统中的所有应用程序之间仲裁资源的最终权限。
每个应用程序ApplicationMaster实际上是一个特定于框架的库,其任务是协调来自ResourceManager的资源,并与NodeManager一起执行和监视任务。

YARN架构
master/slave:RM/NM
Client:向RM提交任务/杀死任务
ApplicationMaster:
- 每个应用程序对应一个AM,AM用于向RM申请资源,用于在NM上启动对应的Task
- 数据切分
- 为每个task向RM申请资源(container,在container里面启动task)
- 与NM通信
- 任务监控
NodeManager:
- 计算;
- 向RM发送心跳、任务执行情况;
- 接收来自RM的亲求,启动Task
- 处理来自AM的命令
ResourceManager:
- 集群中同一时刻对外提供服务的只有一个,负责资源相关
- 处理来自客户端的请求:提交、杀死
- 启动/监控 AM
- 监控NM
container:
- 任务的运行抽象:memory、cpu…
- task是运行在container里面的
- 一个container里可以运行AM,也可以运行map/reduce task
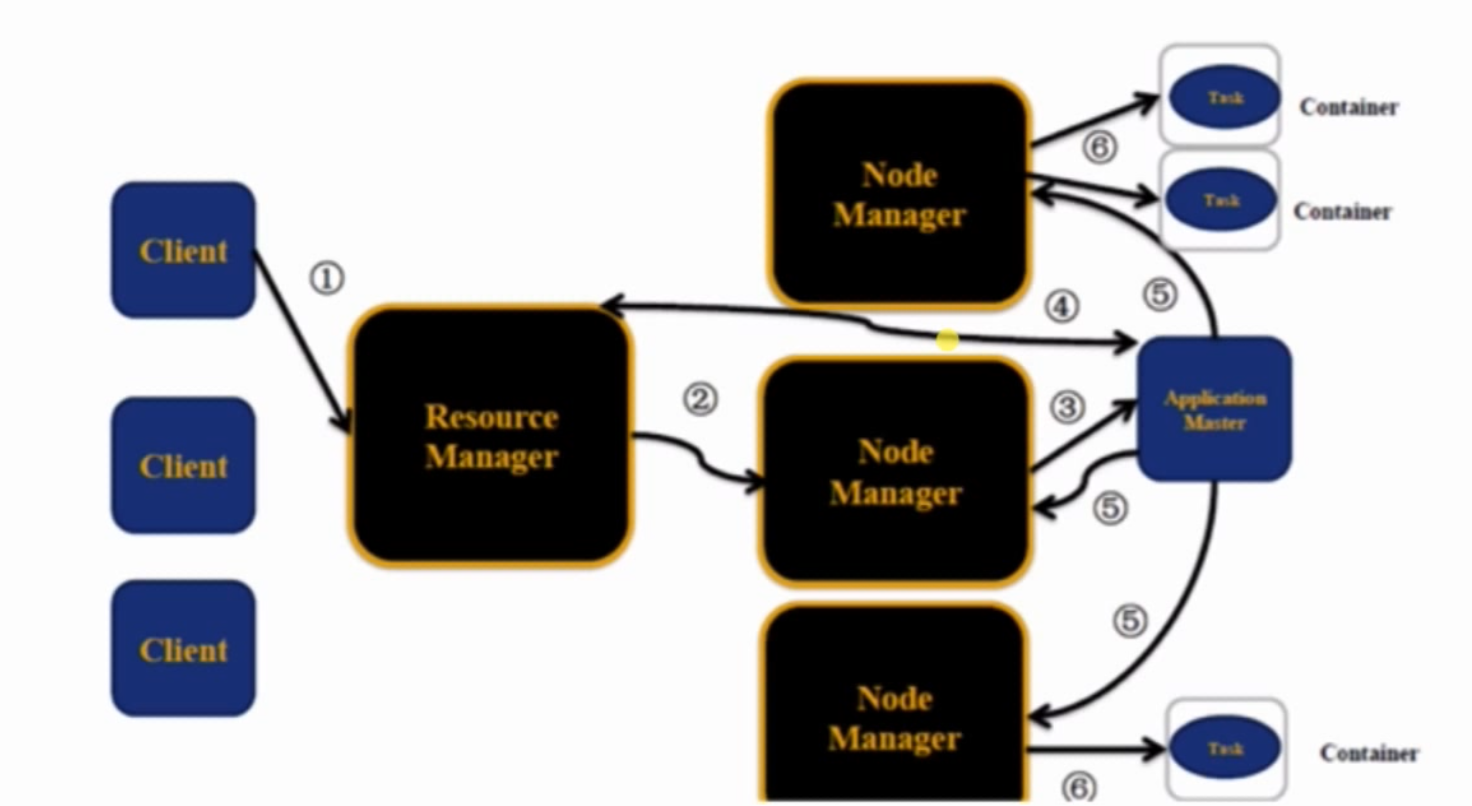
YARN执行流程
流程:client提交作业到RM==>RM在一个NM上先申请第一个container,用于运行AM==>AM注册到RM上去,AM向RM申请资源,返回资源==>到对应的NM上启动Container==>在Container上启动map/reduce task==>然后各种监控开起来
YARN环境搭建
mapreduce在调试的时候是本机运行的,在正式上线时需要放在YARN上。
配置
etc/hadoop/mapred-site.xml:
1 | <configuration> |
etc/hadoop/yarn-site.xml:
1 | <configuration> |
启动:
1 | $ sbin/start-yarn.sh |
界面
1 | ResourceManager - http://localhost:8088/ |
提交作业到YARN运行
1 | $ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar pi 2 3 |






