[TOC]
以电商业务为例,完成一个离线计算系统的技术架构(HDFS+MapReduce)
需求分析
用户行为日志
点击、搜藏、搜索、加入购物车、下单…
推荐
需求
统计页面的浏览量
统计各个省份的浏览量
统计页面的访问量
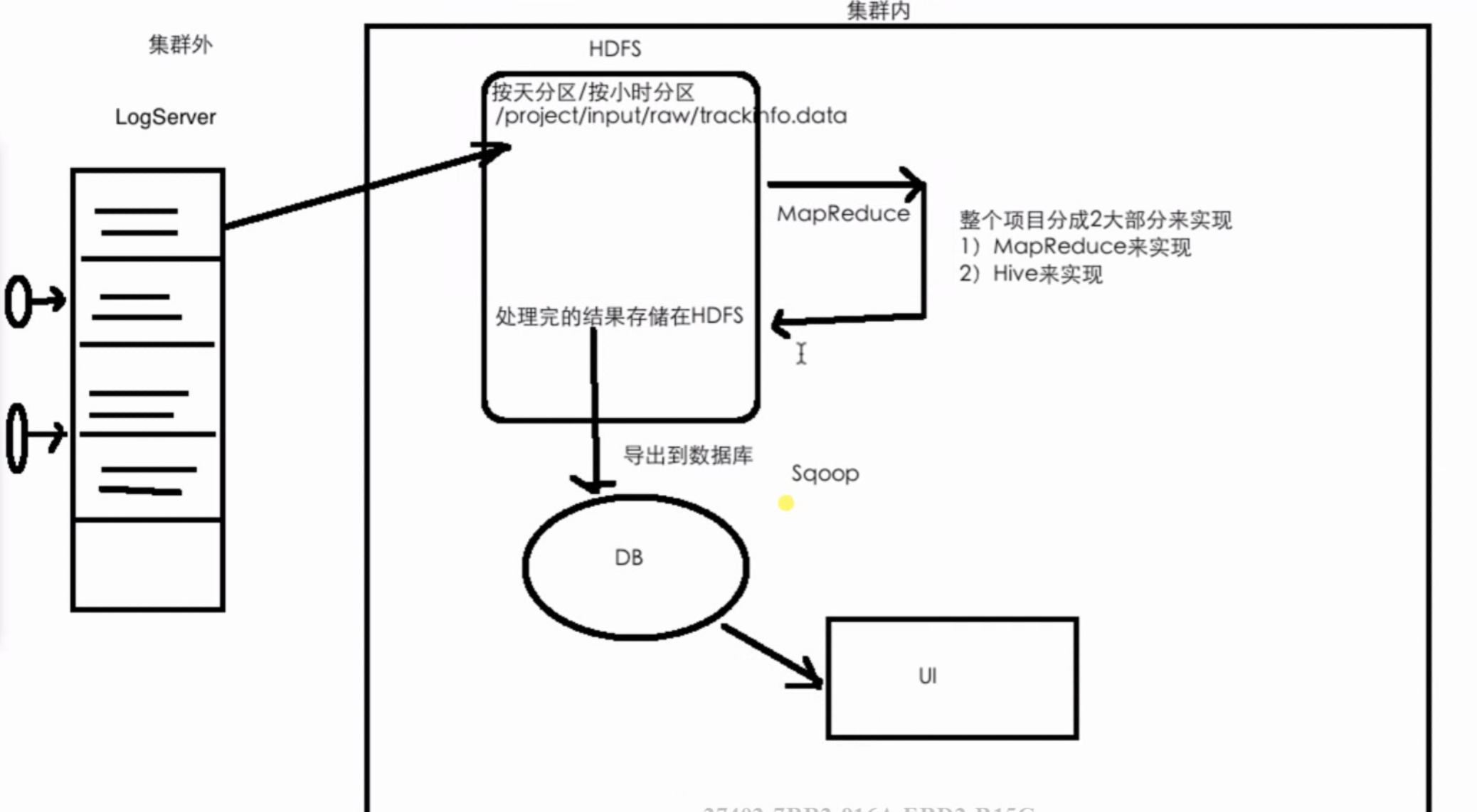
数据处理流程及技术架构(离线计算)
统计页面的浏览量
每行数据都是固定的key,value赋值为1
select count(1) from xxx;
1 | PVStatApp |
统计各个省份的浏览量
select province count(1) from xxx group by province;
地市信息通过IP解析获取
IP库解析
IP解析:在正式项目中通常使用收费服务
这里测试使用qqwry.dat开源库
相关代码
1 | IPParser |
日志解析
将一行日志的ip解析出来,并转换为城市信息
代码
1 | LogParser |
MR统计省份流量
解析出一行log的ip的省份信息,将省份作为key,value是1
代码
1 | ProvinceStatApp |
统计页面的访问量
解析出一行log的url的pageId(有的url没有),将pageId作为key,value是1
1 | ContentUtils // 获取编号 |
ETL-改进优化
目前存在的问题
假设日志数据很大(5T),每个MR都去全量处理待处理的原始日志,非常消耗时间。
解决办法:ETL
ETL:全量数据不方便直接计算,最好是进行一步处理后再进行相应的维度统计分析。
解析出需要的字段:ip ==> 城市信息
去除不需要的字段 ==> 很多
保留字段:ip/time/url/page_id/province/city
其他作业的输入都使用etl文件
代码
1 | ETLApp |
打包到服务器上运行
1 | mvn clean package |
扩展TODO
处理结果的存储
大数据处理完后,目前存在HDFS上。
如果需要前台展示,可采用的方案:使用技术或框架把处理完的结果导出到数据库(mysql,mongoDB)中,然后前台展示。
Sqoop:把HDFS上的统计结果导出到mysql中。
T级别的初始数据,假设一天要处理一次。
可以采用压缩
原始日志一般在集群上会定期删掉,但一次etl的数据一般会存很久(比如一年)。
如果etl的数据存不下,可以把etl的数据先移到冷集群上,热集群就是跑当前数据(比如以一个月、一天为单位),冷集群放不下就要移到其他地方。
etl通常会拆字段,结果是etl的数据比原始数据还大。文本存储方式会全量读取再过滤,会采用列式存储(ORC),比如有100列,只需要访问3列,剩下的97列是不会产生io操作的。






