参考:
第1章 概述
hive是基于HDFS的数据仓库,主要介绍数据仓库和Hive的基本概念
什么是数据仓库
数据仓库
数据仓库是一个面向主题的、集成的、不可更新的、随时间不变化的数据集合,它用于支持企业或组织的决策分析处理。
面向主题:推荐系统
集成:数据来自于关系型数据库、文本..
不可更新:一般只做查询
数据仓库的结构和建立过程
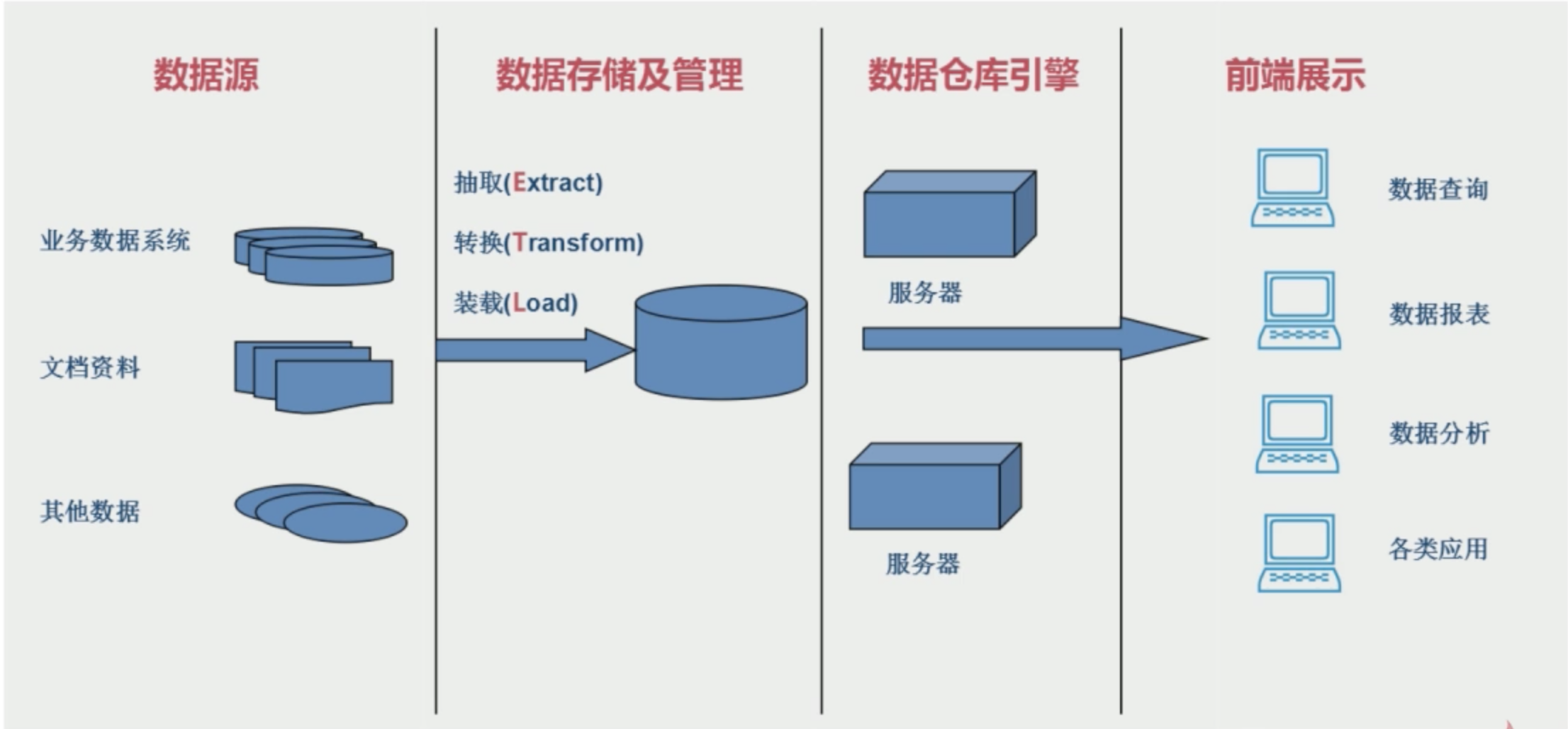
ETL:
抽取Extract:提取不同数据源的数据
转化Transform:转化格式,不同数据源的数据格式可能不一致
装载Load:将满足数据格式的数据装载到数据仓库
OLTP应用于OLAP应用
OLTP应用:联机事务处理,关注的是事物的处理,典型的OLTP应用是银行转账,一般操作频率会比较高;
OLAP应用:联机分析处理,主要面向的是查询,典型的OLAP应用是商品推荐系统,一般不会做删除和更新,数据一般都是历史数据。
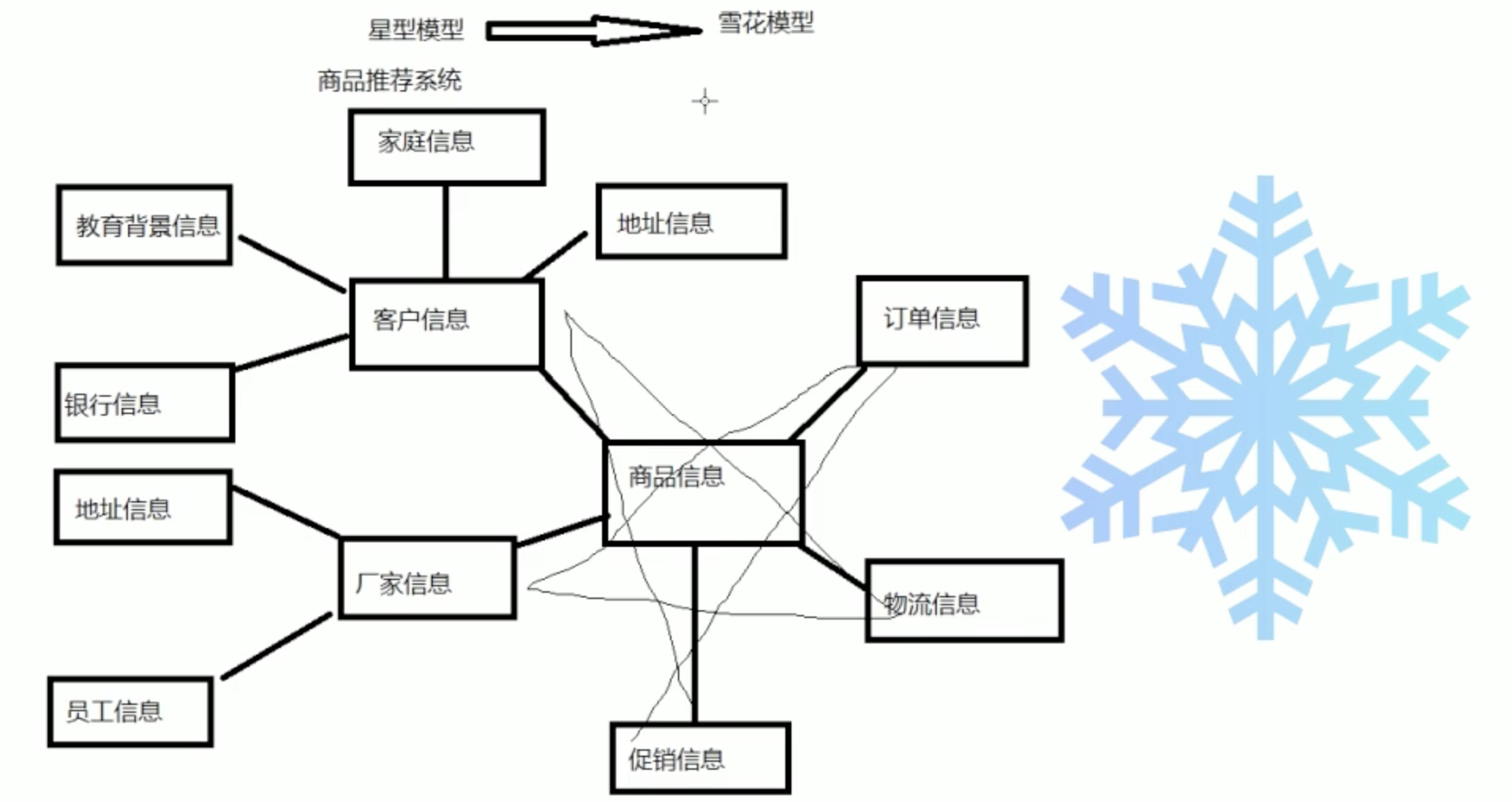
数据仓库中的数据模型
星型模型和雪花模型。星型模型是数据仓库最基本的数据模型,雪花模型是在星型模型的基础上发展起来的。
什么是Hive
Hive是建立在Hadoop HDFS上的数据仓库基础架构;
Hive可以用来进行数据提取转化加载(ETL)
Hive定义了简单的类似SQL查询语言,称为HQL它允许熟悉SQL的用户查询数据
Hive允许熟悉MapRduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作;
Hive是SQL解析引擎,他将SQL语句转移成M/R Job然后在Hadoop执行;
Hive的表其实就是HDFS上的目录/文件;
底层支持多种执行引擎:MR/Tez/Spark
为什么要使用Hive
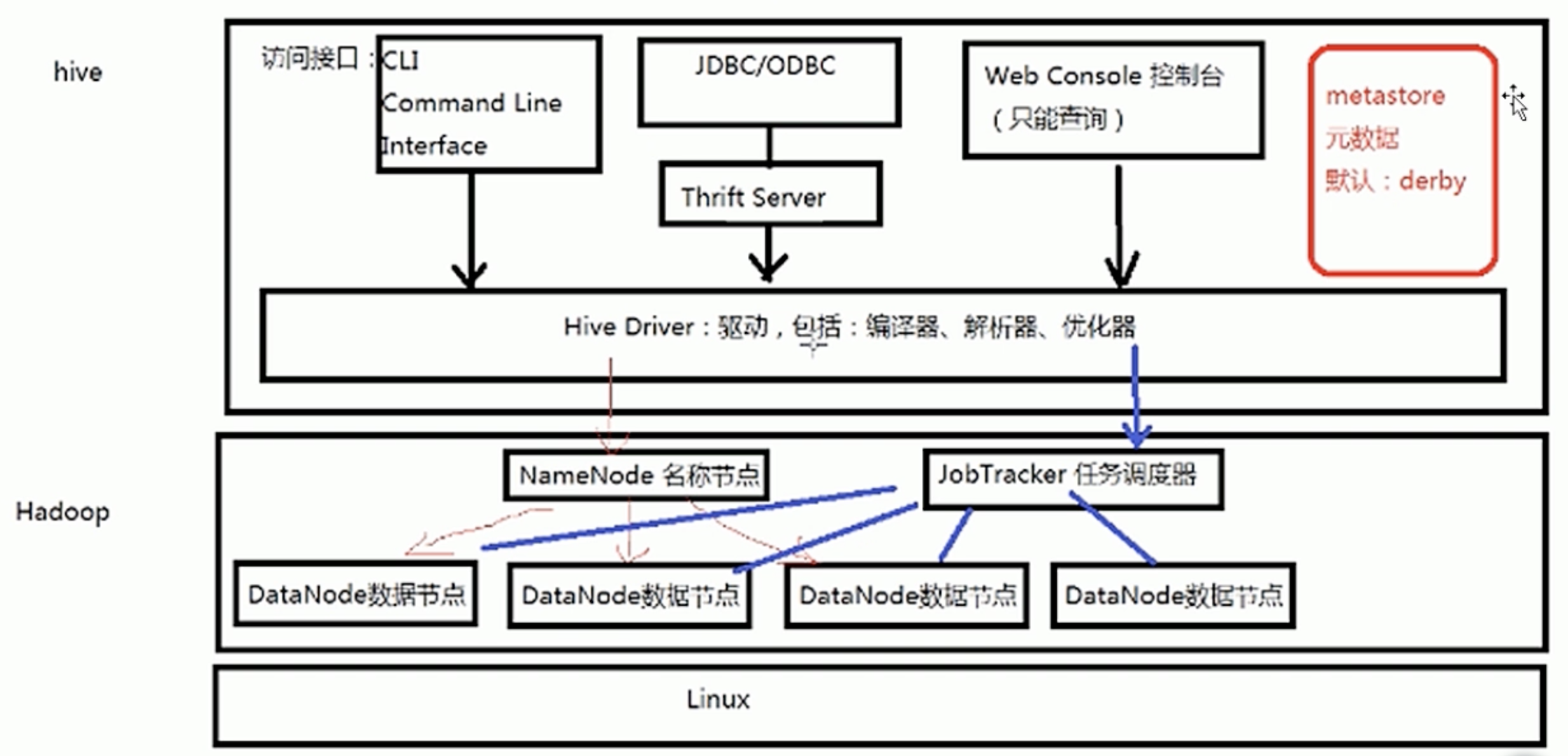
第2章 Hive的体系结构
hive的体系结构,以及与HDFS的关系
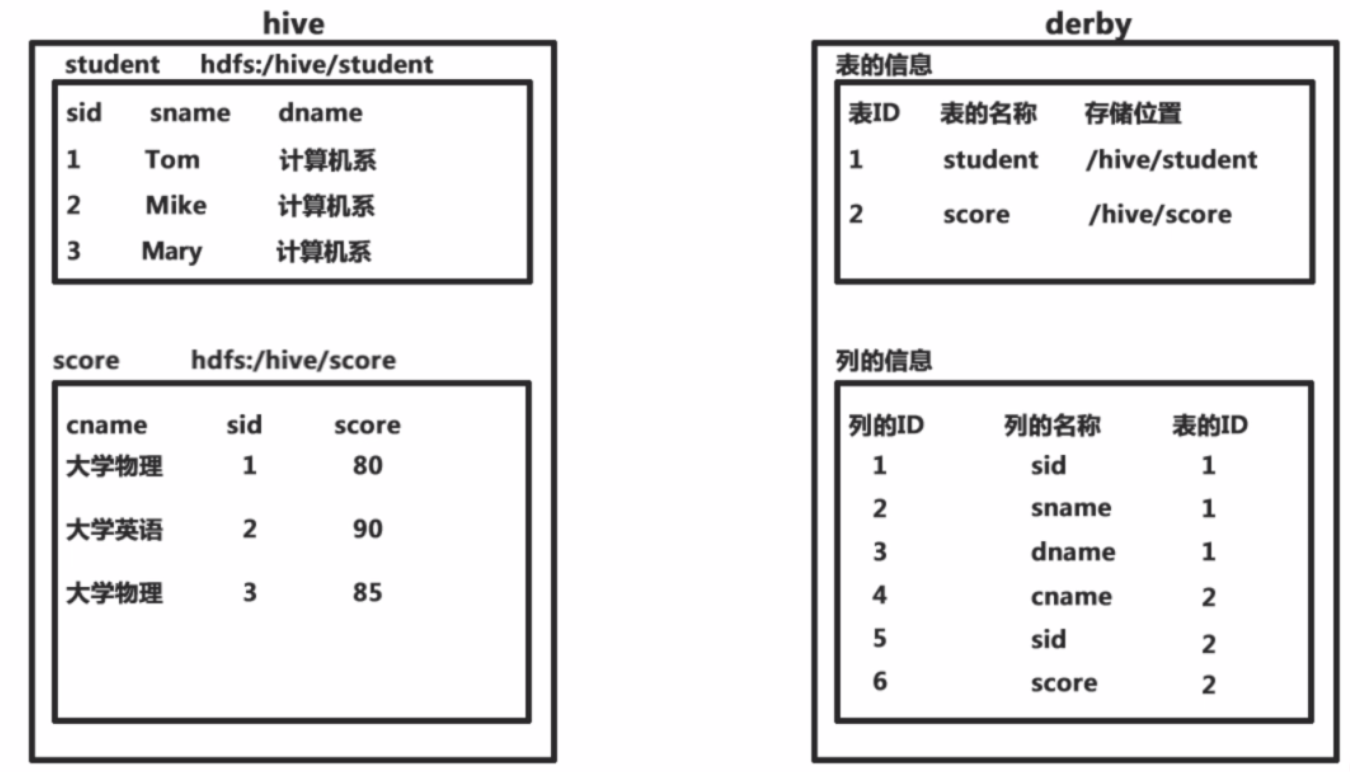
元数据
Hive将元数据存储在(metastore),支持mysql,derby等数据库 (默认存放在derby数据库中)
Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表),表的数据所在目录。
HQL的执行过程
解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划(Plan)的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。

以oracle执行计划为例:
1 | explain plan for select * from emp where deptno10 |
Hive的体系结构
第3章 Hive的安装
演示元数据库的安装以及Hive的安装;包括基于MySQL的hive的安装
安装模式介绍
1 嵌入模式
- 本地durby :元数据信息被存储在Hive自带的Derby数据库中
- 只允许创建一个链接:同一时间只能一个人操作
- 多用于Demo:演示环境2 本地模式
- 元数据信息被存储在MySQL数据库中
- MySQL数据库与Hive运行在同一台物理机器上
- 多用于开发和测试环境3 远程模式
- 元数据信息被存储在MySQL数据库中
- MySQL数据库与Hive运行在不同的物理机器上
- 多用于生产环境(mysql要主从备份,用VIP连接)安装本地模式
安装
apache-hive-3.1.2-bin.tar.gz
conf/hive-env.sh.template
1 | cp hive-env.sh.template hive-env.sh |
hive-site.xml
1 |
|
将mysql-connector-java-5.1.39-bin.jar拷贝到 ./lib下
启动
1 | cd $HIVE_HOME/bin |
第4章 Hive的操作
Hive快速入门(建库/建表/执行HQL)
创建数据库
1 | create database test_db; |
创建一张表
1 | use test_db; |
Hive DDL
参考官网:Hive DDL
DDL: Hive Data Definition Language
数据抽象/结构
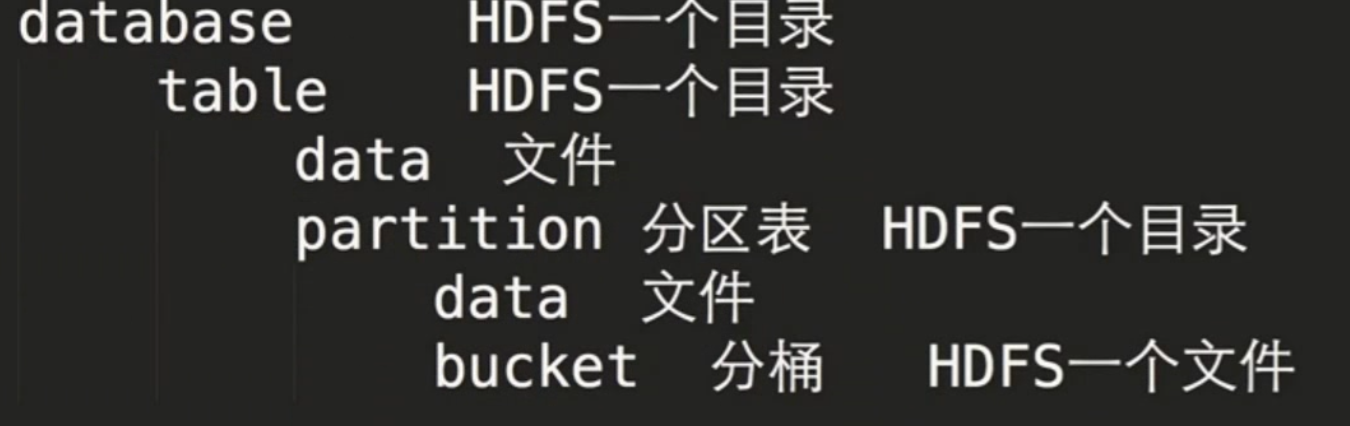
Create Database
1 | CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name`` ``[COMMENT database_comment]`` ``[LOCATION hdfs_path]`` ``[WITH DBPROPERTIES (property_name=property_value, ...)]; |
建表
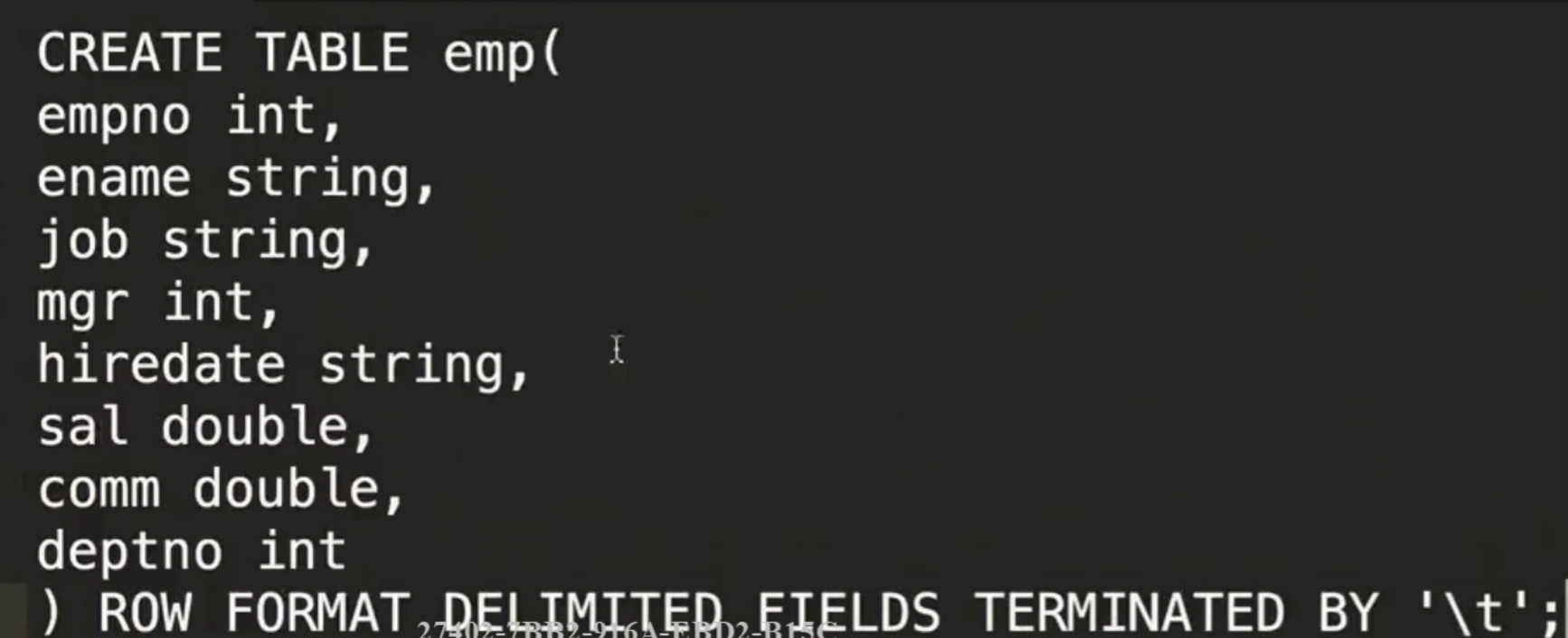
加载表数据

Rename Table
1 | `ALTER TABLE table_name RENAME TO new_table_name;` |
HIVE DML
Loading files into tables
1 | LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] |
LOCAL:本地系统,如果不加,就指HDFS路径
OVERWRITE:是否数据覆盖,如果没有,就是追加
Inserting data into Hive Tables from queries
1 | INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement; |
Writing data into the filesystem from queries
1 | INSERT OVERWRITE [LOCAL] DIRECTORY directory1 |

insert 、update 不建议在大数据Hive下使用!
Hive Query
1 | SELECT [ALL | DISTINCT] select_expr, select_expr, ... |
基本查询
1 | WHERE LIMIT ... |
聚合
1 | max/min/sum/avg |
分组函数:GROUP BY
1 |
JOIN
1 |
执行计划
1 |
else todo
1 | 第4章 Hive的管理 |






