[TOC]
之前讲过用HDFS+MapReduce实现电商日志分析,现在用hive实现相同的功能。
外部表
1 | 查看表结构 |
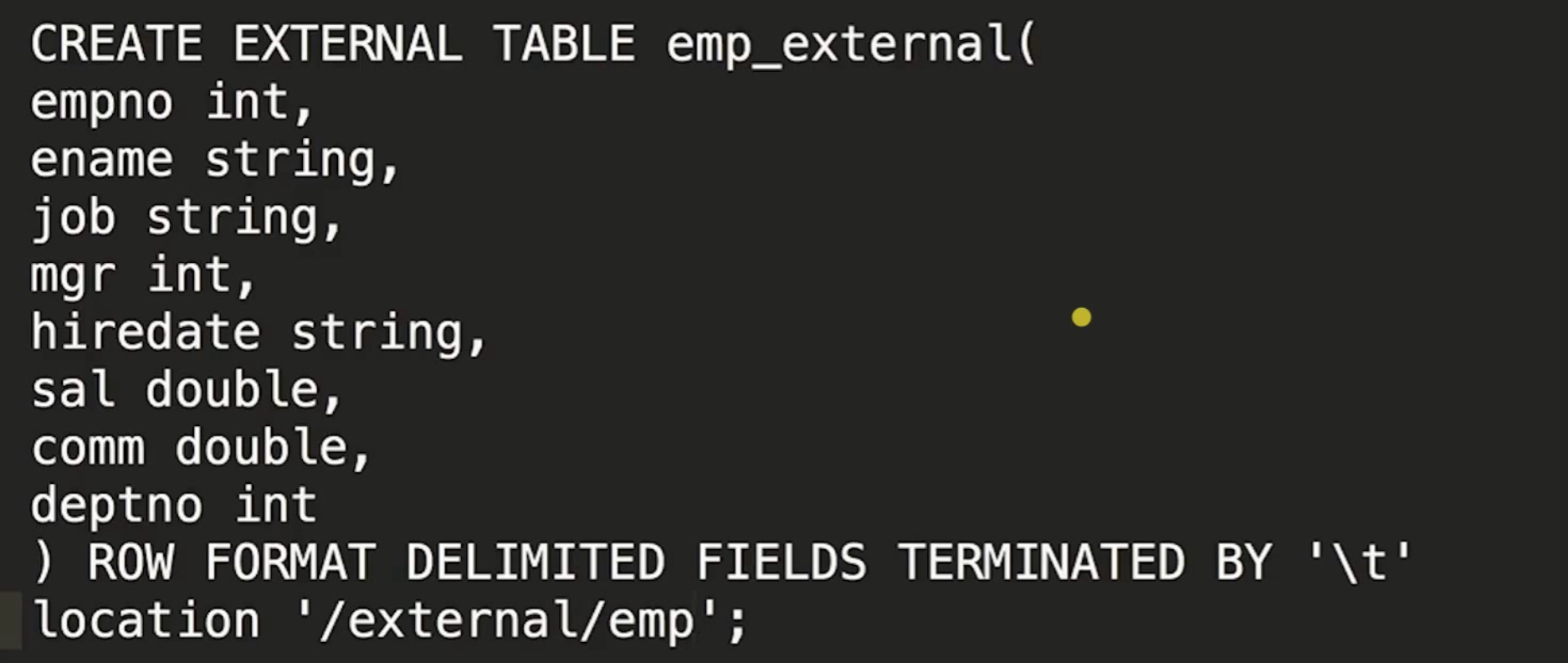
加载数据到外部表
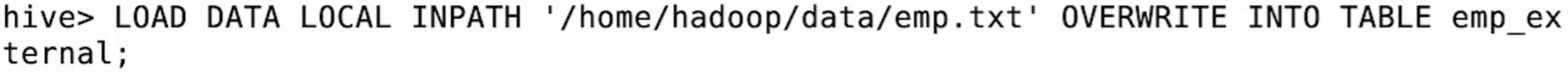
1 | select * from emp_extenal; |
分区表
分区就是HDFS的不同目录,比如按天分区,按性别分区,这样省去了杂乱排序需要的全扫描筛选时间。
比如以下是创建基于性别的分区表:

然后,将性别是F的数据插入对应分区表:
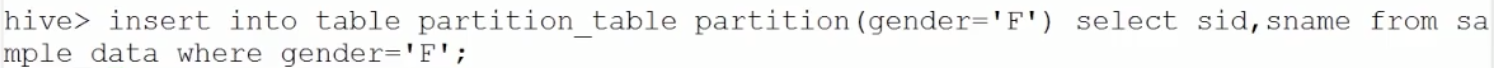
track_info的创建
按天分区,外部表
外部表是将源端数据move到目标端去,而不是copy
1 | create external table track_info( |
基于ETL的数据加载到数据仓库
1、将原始数据放到HDFS
2、跑ETL清洗数据etl.sh
定时执行:crontab表达式进行调度、Azkaban调度(依赖):ETLApp==>其他统计分析
(调度系统)
3、加载数据到hive表(要分区)
1 | LOAD DATA INPATH ‘hdfs://centos01:8020/project/input/etl’ OVERWRITE INTO TABLE track_info partition(day='2013-07-21'); |
使用Hive进行统计分析
1 | 查看数据量(跑mapreduce) |
现在是结果直接打在控制台,怎么存?建立一张目标表,例如省份统计表:
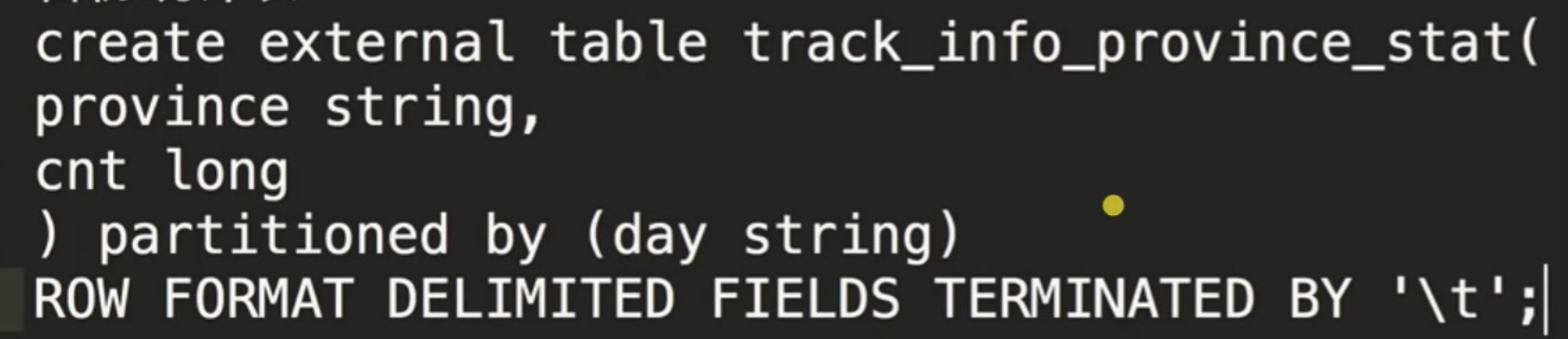
接下来要把一条SQL执行的结果写在结果表中:

结果:

结果数据存在Hive后,怎样使用呢?(例如前端展示)

使用Hive的离线处理方案总结:

把各个步骤,写出shell脚本,然后使用Azkaban定时任务调用。
MapReduce与Hive实现对比
使用Hive相当程度减少了代码量(MR代码 > SQL语句)
else TODO
Hadoop分布式集群搭建
1 | 数据抽取工具: |






