[TOC]
参考:https://www.imooc.com/learn/1044
第1章 概述
本章中将概要介绍Sqoop的作用,以及如何获取Sqoop
预装环境:
hadoop、mysql
基本介绍
Sqoop是什么?
- 开源的数据传输工具,Apache项目
- Hadoop生态圈中的一个第三方模块(将关系型数据库数据和Hadoop平台数据进行传递,将关系型数据和文件类型数据相互转换)
为什么要使用Sqoop?
- 快速实现Hadoop(HDFS/hive/hbase)与传统数据库之间的数据传递
- Sqoop提供了许多数据传输方式(分布式并行导入)
- Sqoop支持多种数据库(mysql,oracle)
常用功能及运行原理
Sqoop常用功能
- 数据导入(关系型 > Hadoop)
- 数据导出(Hadoop > 关系型,将hadoop处理完的计算结果提供给业务系统使用)
- Sqoop作业(保存执行命令中设置的参数,方便重复执行)
- 案例:实现定时数据同步
Sqoop运行原理
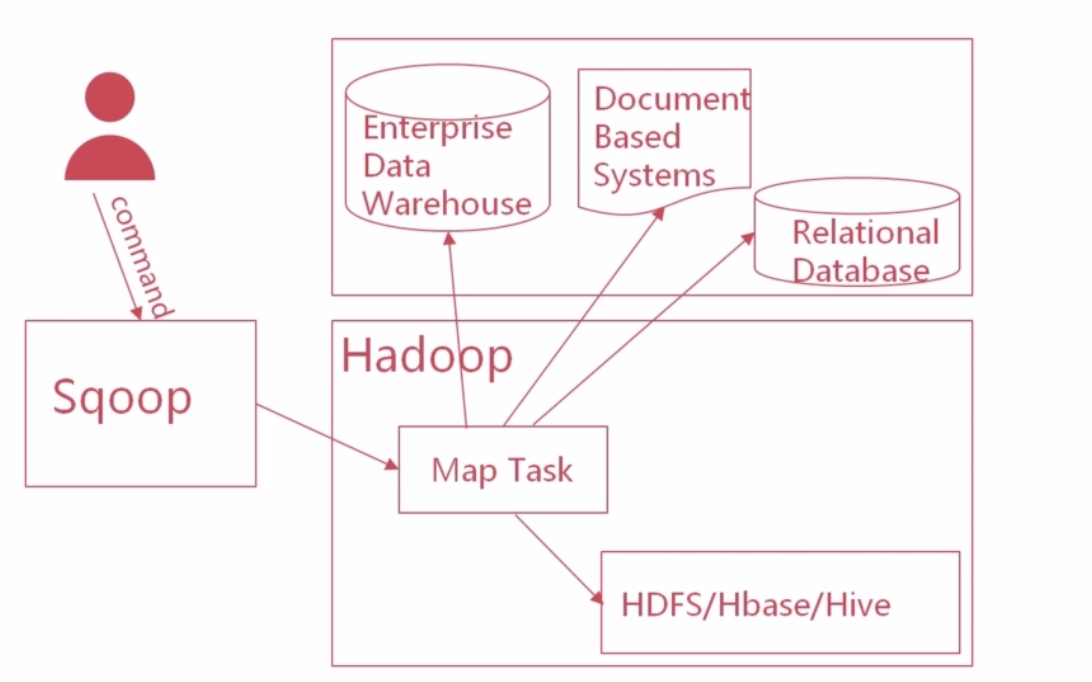
流程:
- 总描述:Sqoop接收到用户的导入命令==> 根据命令生成MapReduce代码,并提交给Hadoop==> Hadoop会启动Map任务,完成数据导入。
- 两个步骤一个中心
- 命令输入步骤:程序员输入command提交给Sqoop(比如导入数据到HDFS),然后Sqoop全权负责导入事宜。首先读取数据表结构,生成运行类打成jar包,提交给Hadoop。
- Map导入步骤:Hadoop收到Sqoop生成的jar包后会启动Map任务,Map任务去读取源数据表的内容,将读取到的数据导入到目标数据库中。
- 一个中心:Map任务(负责核心操作,数据导入导出)
Sqoop核心技术
- 生成MapReduce
- 作业创建(主要用于定时任务执行,例如增量导入)
- 数据映射(自动完成数据类型映射转换,关系型数据类型==> Hadoop相应的数据类型,可自定义映射关系)
- 并行控制(采用Sqoop集群,或多个任务并行进行数据导入导出工作,主要在大型数据导入导出,为了提升性能)
第2章 Sqoop下载与安装
本章中将讲解,如何下载Sqoop安装包以及进行Sqoop环境变量配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| # 下载、解压、环境变量
$ wget http://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.tar.gz
$ tar -zxvf sqoop-1.4.7.tar.gz
$ vi ~/.bash_profile
export SQOOP_HOME=/opt/sqoop-1.4.7
export PATH=$SQOOP_HOME/bin:$PATH
$ source ~/.bash_profile
$ echo $SQOOP_HOME
# 配置文件
$ cd conf/
$ cp sqoop-env-template.sh sqoop-env.sh
$ vi sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/hadoop-3.1.2
export HADOOP_MAPRED_HOME=/opt/hadoop-3.1.2
# 进入bin目录,修改文件,注释掉liux中没装的项目:HBASE_HOME HCAT_HOME ACCUMULO_HOME
$ vi configure-sqoop
$ sqoop version
错误: 找不到或无法加载主类 org.apache.sqoop.Sqoop
# 解决方案:
# 进入bin 修改sqoop,最后一行,如下:
# exec ${HADOOP_COMMON_HOME}/bin/hadoop org.apache.sqoop.Sqoop "$@"
exec ${HADOOP_COMMON_HOME}/bin/hadoop jar $SQOOP_HOME/lib/sqoop-1.4.7.jar org.apache.sqoop.Sqoop "$@"
# sqoop-1.4.7.jar是不存在的,需要下载sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz解压,将sqoop-1.4.7.jar取出来,放到$SQOOP_HOME/lib/ 下
# 使用帮助
$ sqoop help import
|
第3章 Sqoop导入
全表导入
本章中将讲解,如何将数据分别以全表和增量方式(两种增量方式对比append和lastmodified两种模式)导入HDFS
1
2
3
4
5
6
7
8
9
10
11
12
13
| $ hadoop fs -mkdir /user/root/movies
# sqoop import (控制参数)(导入参数)
# -m 1 单任务执行
# 默认逐行导入,每列数据用 ‘,’ 分隔
$ sqoop import --connect jdbc:mysql://10.211.55.6:3306/mxx_test --username machine --password 4869 --table topMovie250 -m 1 --target-dir /user/root/movies/topMovie250
# 如果报错找不到类,就把对应的jar包放在$SQOOP_HOME/lib下
# 成功的话,会启动mapreduce作业
2019-09-05 07:41:10,463 INFO mapreduce.ImportJobBase: Transferred 109.9932 KB in 59.5167 seconds (1.8481 KB/sec)
2019-09-05 07:41:10,468 INFO mapreduce.ImportJobBase: Retrieved 250 records.
$ hadoop fs -ls /user/root/movies
$ hadoop fs -cat /user/root/movies/topMovie250/*
|
限制范围导入
导入rank>200的rank和movieName
2种方法:
1
2
3
4
5
6
7
8
9
10
| colmums:指定要导入的列
-- colmums 列名1,列名2
where:
-- where <条件>
$ sqoop import --connect jdbc:mysql://10.211.55.6:3306/mxx_test --username machine --password 4869 --table topMovie250 -m 1 --target-dir /user/root/movies/movieRankAndName --columns 'rank,movieName' --where 'rank>200'
-- query <SQL>
$ sqoop import --connect jdbc:mysql://10.211.55.6:3306/mxx_test --username machine --password 4869 -m 1 --target-dir /user/root/movies/movieFreeSQL --query "select rank,movieName from topMovie250 where rank>200 and \$CONDITIONS"
|
增量导入
在生产系统中很常用,比如系统当天凌晨需要将昨天的交易数据抽取出来导入到HDFS中做并行计算。
意图:持续将源数据导入到存储位置,但每次只会将源数据中新增内容导入到目标地址
核心参数:
1
2
3
| -check-column 检查指定列
-last-value 上一次导入中检查列的最大值
-incremental 标识增量导入
|
append模式
意图:对数据进行附加,不支持更新数据。
应用:数据只累加不修改,如日志数据搜集
lastmodified模式
意图:在源表中数据更新的时候使用
演示apend模式
1
2
3
4
5
| # 先导入rank<=100的数据(rank,movieName)
$ sqoop import --connect jdbc:mysql://10.211.55.6:3306/mxx_test --username machine --password 4869 -m 1 --target-dir /user/root/movies/movieAppend --query "select rank,movieName from topMovie250 where rank<=100 and \$CONDITIONS"
# append 把100以后的数据全部追加到hdfs中
$ sqoop import --connect jdbc:mysql://10.211.55.6:3306/mxx_test --username machine --password 4869 --table topMovie250 -m 1 --target-dir /user/root/movies/movieAppend --columns 'rank,movieName' --check-column rank --incremental append --last-value 100
|
演示lastmodified模式
1
2
3
4
5
6
7
8
| # 先全量导入userInfo表
$ sqoop import --connect jdbc:mysql://10.211.55.6:3306/mxx_test --username machine --password 4869 --table userInfo -m 1 --target-dir /user/root/userInfo
# 然后修改userInfo
# --last-value 上次存储(修改前)的最大时间值
$ sqoop import --connect jdbc:mysql://10.211.55.6:3306/mxx_test --username machine --password 4869 --table userInfo -m 1 --target-dir /user/root/userInfo --check-column last_mod --incremental lastmodified --last-value "2019-09-05 22:12:04" --append
# 会将last-value指定时间后的修改操作更新到hdfs
|
第4章 Sqoop导出
本章中将概要介绍如何将HDFS的数据导出至Mysql的操作
在Hadoop并行计算后,将结果导出到mysql进行其他业务
1
2
3
4
| sqoop export
2种模式:
insert模式(数据附加导出,不支持更新。原理是将数据转化为insert语句,执行SQL插入)
updat模式(支持数据更新。原理是将数据转化为update语句,执行更新操作)
|
演示:略
第5章 Sqoop作业制定
本章中将讲解,Sqoop基本作业的创建与查看以及如何 通过定时调度器调度Sqoop抽取作业。
数据增量导入作业
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # 创建密码的隐藏文件
echo -n "123456" > sqoopPWD.pwd
hdfs dfs -mkdir -p /sqoop/pwd
hdfs dfs -put sqoopPWD.pwd /sqoop/pwd
hdfs dfs -chmod 400 /sqoop/pwd/sqoopPWD.pwd
# 创建job
sqoop job \
--create movieJob \
-- import \
--connect jdbc:mysql://localhost:3306/mxx_test \
--username root \
--password-file /sqoop/pwd/sqoopPWD.pwd \
--table topMovie250 -m 1 \
--target-dir /user/mxx/movies/movieJob \
--incremental append --check-column rank \
--last-value 1 \
--verbose
$ sqoop job --list
$ sqoop job --show movieJob
# 执行job
$ sqoop job --exec movieJob
# 增加一条数据,重复执行myJob,此时lastValue值已经被更改,它可以接着append
|
定时作业调度
比如每天凌晨调度一次
实现定时的方式:
- Oozie,定时调度Sqoop任务
- 编写定时程序,定时程序定时调度Sqoop任务
- 使用Centos自带的调度器Crontab实现sqoop任务定时调度
这里介绍使用Centos自带的调度器Crontab实现sqoop任务定时调度
1
2
3
4
5
6
7
8
9
10
| cd $SQOOP_HOME
vi sqoop_incremental.sh
#!/bin/bash
/home/machine/apps/sqoop-1.4.6-cdh5.16.1/bin/sqoop job --exec movieJob > /home/machine/apps/sqoop-1.4.6-cdh5.16.1/movieJob.out 2>&1 &
crontab -e
*/1 * * * * sh /home/machine/apps/sqoop-1.4.6-cdh5.16.1/sqoop_incremental.sh
# 增加一条数据,myJob会定时执行,此时lastValue值已经被更改,它可以接着append
|
第6章 总结
对本课程所学内容进行总结
略






