[TOC]
参考:
Flume概述 问题引入 数据如何从java后台服务器(业务系统如springboot) 到 大数据集群(Hadooop生态圈)?
一般这两套不会使用一台服务器
后台跟页面交互,必须要保证实时性,反应要快。而大数据集群,跟多时候可以离线处理数据,实时要求不高。
数据来源:
业务数据:订单、支付 ===》Mysql
访问日志:访问、点击、搜索===>磁盘文本,日志
这个数据采集的工具:Flume。
日志采集系统方案:Flume+Kafka+HDFS
https://blog.csdn.net/weixin_38750084/article/details/82861555
https://www.cnblogs.com/zyfd/p/9578252.html
Flume定义 文档:http://flume.apache.org/
Java后台日志每时每刻产生数据,怎么存到HDFS里去?
一:实时存到HDFS?每产生一个用户行为就写一个HDFS put? ===》不可能,效率太低。
二:每天产生的日志写成一个XXX.log文件,然后调用定时任务每天凌晨写一次HDFS put?
数据量大?不是问题,HDFS本来就擅长处理大数据。
实时性?一天的数据,只能当天凌晨做导入,还需要分析计算。造成的效果是,我当天浏览了商品,到了第二天才去给我相关推送。而我们现在的效果是,刚浏览了商品,立马就能得到推荐。怎么做?需要一个中间软件实时上传数据到HDFS===》Flume
定义
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
kafka: 流式的,对应实时系统
flume:对应离线系统
Flume基础架构
Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的,是Flume数据传输的基本单元。
Agent主要有3个部分组成,Source、Channel、Sink。
Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。
Flume快速入门 Flume安装 1 2 3 4 5 6 7 http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.16.1.tar.gz Flume运行在JVM之上 进入conf vi flume-env.sh 修改JAVA_HOME就行
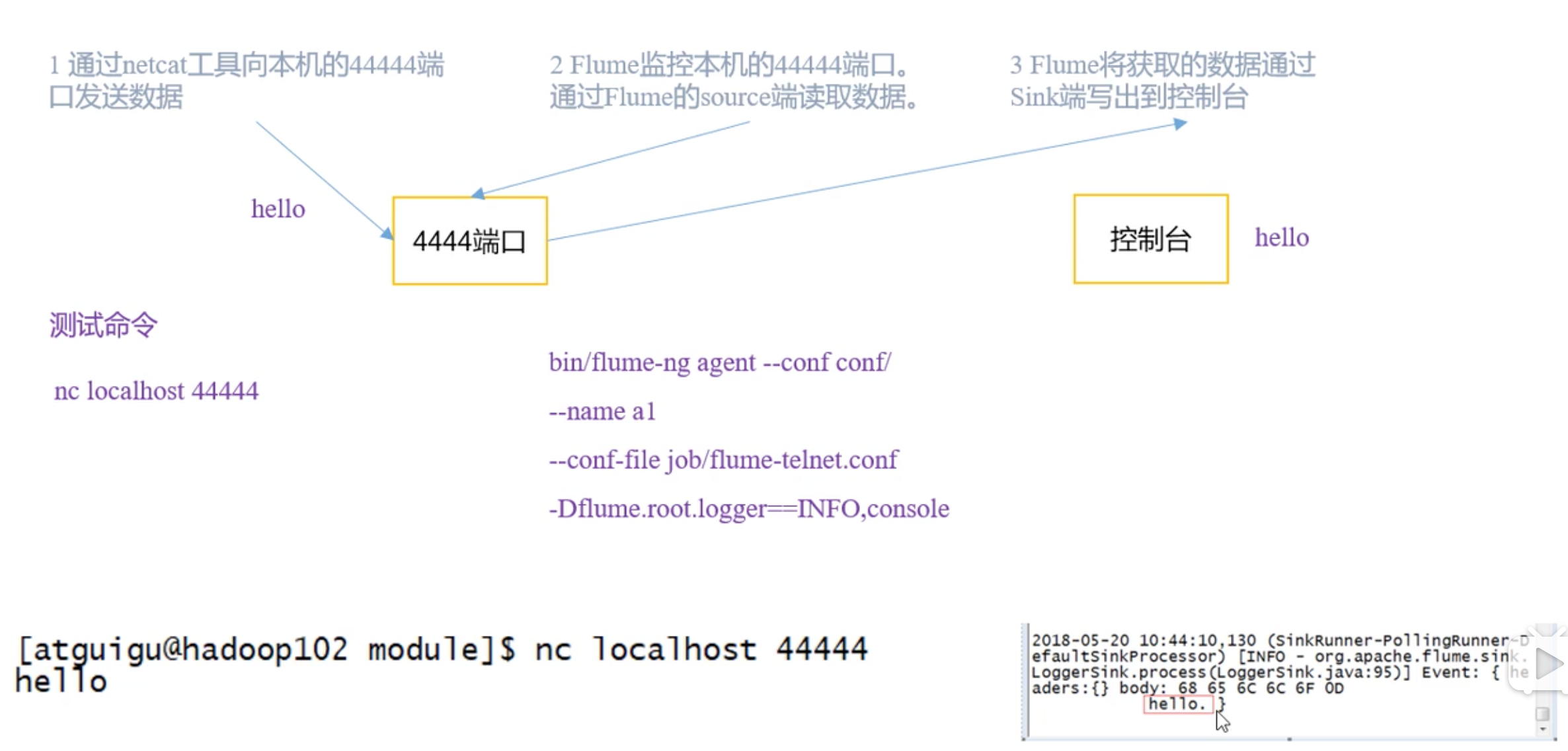
官方案例–监控端口数据 案例需求:首先,Flume监控本机44444端口,然后通过telnet工具向本机44444端口发送消息,最后Flume将监听的数据实时显示在控制台。
分析:
NetCatSource LoggerSink
配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 sudo yum install -y nc # 进入flume home mkdir job cd job/ touch netcat-flume-logger.conf 文件来自: http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.16.1/FlumeUserGuide.html 1000个事件,一次事务传输100个事件 # example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动
1 2 3 4 5 6 7 8 9 10 $ bin/flume-ng agent --conf conf/ --conf-file job/netcat-flume-logger.conf --name a1 -Dflume.root.logger=INFO,console # 此时本机作为nc服务端启动了,它监听的是localhost:44444端口 # 在mac上开一个客户端去连 nc -u 10.211.55.14 44444 # 服务端会显示: Event: { headers:{} body: 68 65 6C 6C 6F hello } $ bin/flume-ng agent -c conf/ -f job/netcat-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console
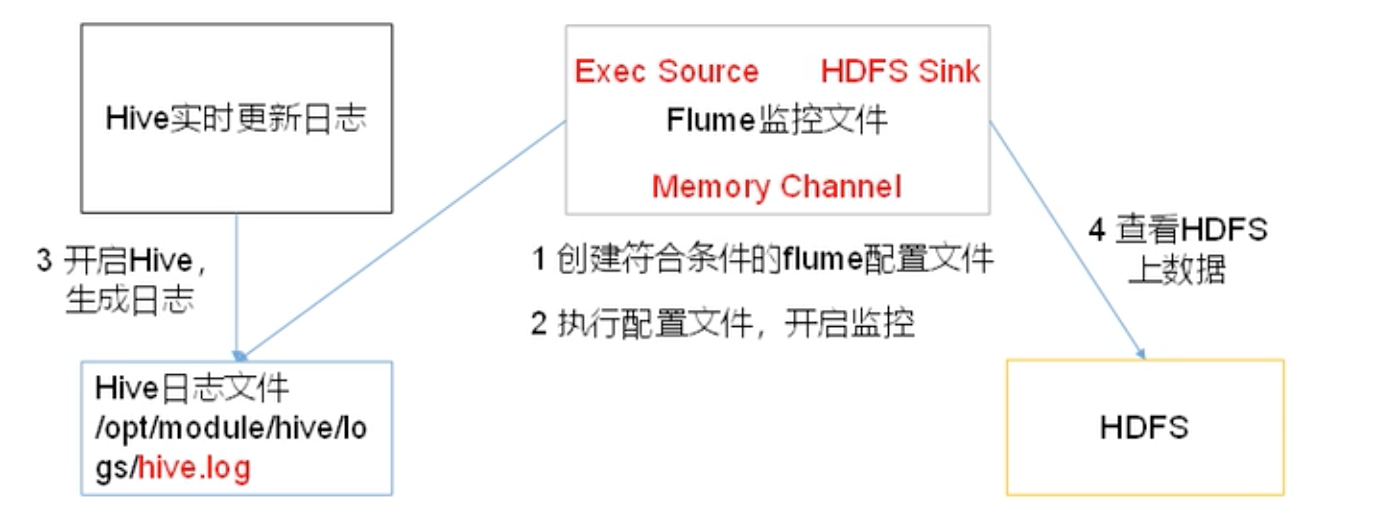
案例–实时监控单个追加文件 案例需求:实时监控Hive日志,并上传到HDFS中
先做输出到logger的案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 exec 监控本地文件 tail -f 可以监控文件变化 Hive 设置日志存储目录: https://blog.csdn.net/qq_35495339/article/details/95105779 touch file-flume-logger.conf # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -f /home/machine/apps/hive-1.1.0-cdh5.16.1/logs/hive.log # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 bin/flume-ng agent -c conf/ -f job/file-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console # 这时默认会先打印10条数据:Event # 启动hive,写show databases; 触发hive.log日志改变,这时,flume logger控制台会实时打印变化的日志。
现在做输出到HDFS的案例:HDFS sink
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 Flume要想将数据输出到HDFS,必须持有Hadoop相关jar包 # 生产环境下以下配置很重要 # 滚动文件 hdfs.rollInterval hdfs.rollSize hdfs.rollCount hdfs.batchSize # 滚动文件夹(Hive也按天分区) hdfs.round hdfs.roundValue hdfs.roundUnit hdfs.useLocalTimeStamp = true 以下是生产环境常用: file-flume-hdfs.conf # ============================= # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /home/machine/apps/hive-1.1.0-cdh5.16.1/logs/hive.log # Describe the sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://localhost:9000/flume/%Y%m%d/%H # 上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs- # 是否按照时间滚动文件夹 a1.sinks.k1.hdfs.round = true # 多少时间单位创建一个新的文件夹 a1.sinks.k1.hdfs.roundValue = 1 # 重新定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour # 是否使用本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true # 积攒多少个Event才flush到HDFS一次 a1.sinks.k1.hdfs.batchSize = 1000 # 设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream # 多久生成一个新的文件,生产环境不要设置30s,太快了 a1.sinks.k1.hdfs.rollInterval = 30 # 设置每个文件的滚动大小,不超过128m,即hdfs块大小 a1.sinks.k1.hdfs.rollSize = 134217700 # 文件的滚动与Event数量无关 a1.sinks.k1.hdfs.rollCount = 0 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 bin/flume-ng agent -c conf/ -f job/file-flume-hdfs.conf -n a1 # 会自动在hdfs上创建flume文件夹 # 每30s会滚动一个文件,但前提是这30s内有新数据进来 # 去hive里做一个触发,过30s会滚动一个新文件, logs-.1568271636815
案例–实时监控目录下多个新文件 tail -f 是一行一行读的,现在有个目录,不停的放新文件,且文件放好后,不再修改。
spooldir source
只要目录有新文件就上传,不是说文件有新内容
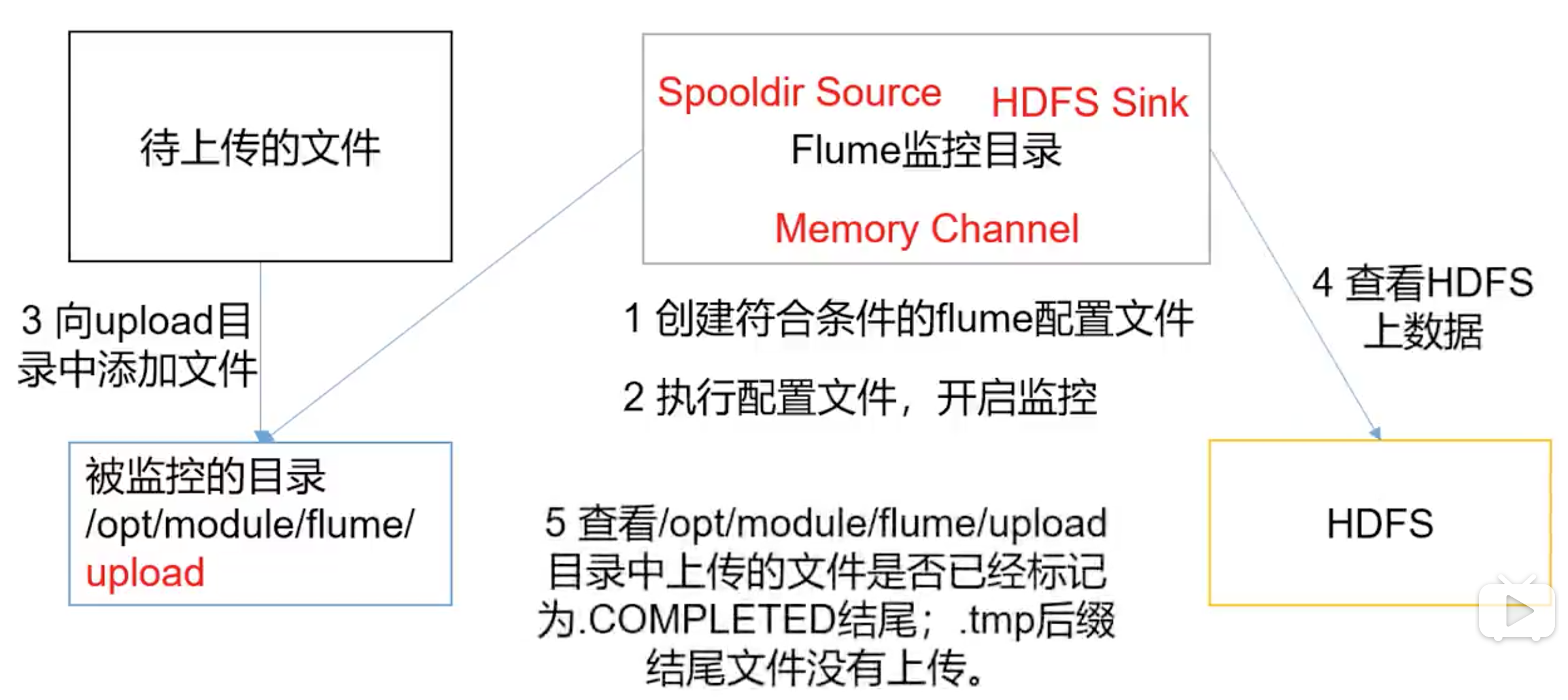
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 touch dir-flume-hdfs.conf 复制file-flume-hdfs.conf fileSuffix: 默认.COMPLETED 。 通过文件后缀过滤掉已添加的文件 # 要上传/不上传 的文件 includePattern ignorePattern 修改以下内容: # Describe/configure the source a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /home/machine/apps/flume-1.6.0-cdh5.16.1/upload # 准备txt文件 bin/flume-ng agent -c conf/ -f job/dir-flume-hdfs.conf -n a1 # 向upload写一个文件 cp 1.txt upload/ ll upload/ 1.txt.COMPLETED # 不可能监控动态变化的数据,不要创建文件后再修改文件,不要取同名文件,不要取名后缀为.COMPLETED的文件 # 被监控文件夹每500ms扫描一次文件变动 # 忽略所有以.tmp结尾的文件,不上传 a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # 适合场景:.tmp表示数据正在实时追加,追加完后才去掉tmp后缀,这时,上传改文件,并加上.COMPLETED后缀
产生日志策略:
1 2 在生产一个文件的数据时(追加数据是一个过程),以XXX.tmp命令,这样可以让spooldir忽略监控。 当文件生产完毕,不再修改时,修改其命名,去掉tmp后缀,这时spooldir会立马监控到该文件并且上传,然后加上.COMPLETED
案例–实时监控目录下多个追加文件 目录下的多个新文件,都能被监控
souce对比:
exec: 监控实时追加的文件,不保证数据不丢失。
spooldir:监控目录下产生的新文件,但不监控文件内容变化,延迟高,不实时。
taildir : 支持断点续传,数据不丢失,且实时监控多个文件夹的多个文件 。
需求:监控一个文件夹的 新文件和旧文件追加,并上传至HDFS
先做taildir — logger
1 2 3 4 5 6 7 8 9 10 cd job touch files-flume-logger.conf # 创建files目录 mkdir files cd files/ touch file1.txt touch file2.txt # 写files-flume-logger.conf
files-flume-logger.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source # positionFile: 断点续传的记录文件 a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 f2 a1.sources.r1.filegroups.f1 = /home/machine/apps/flume-1.6.0-cdh5.16.1/files/file1.txt a1.sources.r1.filegroups.f2 = /home/machine/apps/flume-1.6.0-cdh5.16.1/files/file2.txt a1.sources.r1.positionFile = /home/machine/apps/flume-1.6.0-cdh5.16.1/position/position.json # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
运行
1 2 3 4 5 6 bin/flume-ng agent --conf conf/ --conf-file job/files-flume-logger.conf --name a1 -Dflume.root.logger=INFO,console echo hello >> file1.txt echo flume >> file2.txt # 在控制台看到了变化
测试断点续传
1 2 3 4 5 把flume监控手动挂掉。然后生产数据 echo hahah >> file2.txt 重启后,可以断点续传
测试是否可以在一个组直接放2个文件
1 2 3 4 5 a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /home/machine/apps/flume-1.6.0-cdh5.16.1/files/file1.txt a1.sources.r1.filegroups.f1 = /home/machine/apps/flume-1.6.0-cdh5.16.1/files/file2.txt # 结论是这种写法不行,一个组只能配一个文件,否则会被后者覆盖
Flume进阶 案例:flume消费kafka数据到hdfs 需求
1 2 3 kafka > kafka source > flume channal > hdfs sink > hdfs Source组件实时去消费Kafka业务Topic获取数据,将消费后的数据通过Flume Sink组件发送到HDFS进行存储。
环境
1 Kafka、Flume、Hadoop(HDFS可用)
启动kafka简单生产者
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 启动zk $ ZOOKEEPER_HOME/bin/zkServer.sh start # 启动kafka # 启动阻塞进程 bin/kafka-server-start.sh config/server.properties # 启动守护进行 # bin/kafka-server-start.sh -daemon config/server.propertie # 创建2个topic ./kafka-topics.sh --create --zookeeper mxxcentos7:2181 --replication-factor 1 --partitions 3 --topic my-kafka-topic ./kafka-topics.sh --create --zookeeper mxxcentos7:2181 --replication-factor 1 --partitions 3 --topic my-kafka-topic2 # 查看Topic: ./kafka-topics.sh --list --zookeeper mxxcentos7:2181 # 启动生产者: ./kafka-console-producer.sh --broker-list mxxcentos7:9092 --topic my-kafka-topic ./kafka-console-producer.sh --broker-list mxxcentos7:9092 --topic my-kafka-topic2 # 启动消费者:./kafka-console-consumer.sh --bootstrap-server mxxcentos7:9092 --topic my-kafka-topic --from-beginning
kafka - flume - logger测试 先做一个sink为logger的测试一下
1 2 cd apps/flume-1.6.0-cdh5.16.1/job/ touch kafka-flume-logger.conf
kafka-flume-logger.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 # 给agent组件命名 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置 kafka source a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource # List of brokers in the Kafka cluster used by the source (以逗号分隔) a1.sources.r1.kafka.bootstrap.servers = mxxcentos7:9092 # Comma-separated(以逗号分隔) list of topics the kafka consumer will read messages from. a1.sources.r1.kafka.topics = my-kafka-topic,my-kafka-topic2 # 其他可选项 # Maximum number of messages written to Channel in one batch (default 1000) # a1.sources.r1.batchSize = 5000 # Maximum time (in ms) before a batch will be written to Channel The batch will be written whenever the first of size and time will be reached. (default 1000) # a1.sources.r1.batchDurationMillis = = 2000 # Regex that defines set of topics the source is subscribed on. This property has higher priority than kafka.topics and overrides kafka.topics if exists. # a1.sources.r1.kafka.topics.regex # Unique identified of consumer group. Setting the same id in multiple sources or agents indicates that they are part of the same consumer group # a1.sources.r1.kafka.consumer.group.id = custom.g.id # 配置 sink a1.sinks.k1.type = logger # 配置channels:mem类型,1000个事件,每次传10个 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 将sources和sinks绑定到channels a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动
1 2 3 4 bin/flume-ng agent --conf conf/ --conf-file job/kafka-flume-logger.conf --name a1 -Dflume.root.logger=INFO,console # 在kafka生产者里生产数据,看logger sink 的接受效果,如下 2019-11-05 14:24:50,615 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{topic=my-kafka-topic, partition=0, timestamp=1572935089618} body: 78 69 78 69 78 69 xixixi }
kafka - flume - hdfs测试 将上面案例的sink改成hdfs sink
1 2 3 4 5 6 # 开启hdfs start-dfs.sh # mxxcentos7:50070 cd job/ touch kafka-flume-hdfs.conf
kafka-flume-hdfs.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 # 给agent组件命名 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置 kafka source a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource # List of brokers in the Kafka cluster used by the source (以逗号分隔) a1.sources.r1.kafka.bootstrap.servers = mxxcentos7:9092 # Comma-separated(以逗号分隔) list of topics the kafka consumer will read messages from. a1.sources.r1.kafka.topics = my-kafka-topic,my-kafka-topic2 # --------修改的部分 start------------------- # 配置 sink a1.sinks.k1.type = hdfs # 按小时分目录(也可以按天) a1.sinks.k1.hdfs.path = hdfs://mxxcentos7:9000/report-form-data/flume/%{topic}/%Y%m%d/%H # 上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs- # 设置滚动文件夹规则 # 是否按照时间滚动文件夹(没达到hdfs.batchSize但是达到了指定时间,也要产生滚动) a1.sinks.k1.hdfs.round = true # 重新定义时间单位 a1.sinks.k1.hdfs.roundUnit = hour # 多少时间单位创建一个新的文件夹(与hdfs.roundUnit,hdfs.path配合) a1.sinks.k1.hdfs.roundValue = 1 # 是否使用本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true # 积攒多少个Event才flush到HDFS一次 a1.sinks.k1.hdfs.batchSize = 1000 # 设置文件类型,可支持压缩 a1.sinks.k1.hdfs.fileType = DataStream # 设置滚动文件规则 # 多久生成一个新的文件,生产环境不要设置30s,太快了 a1.sinks.k1.hdfs.rollInterval = 30 # 设置每个文件的滚动大小,不超过128m,即hdfs块大小 a1.sinks.k1.hdfs.rollSize = 134217700 # 文件的滚动与Event数量无关 a1.sinks.k1.hdfs.rollCount = 0 # --------修改的部分 end ------------------- # 配置channels:mem类型,1000个事件,每次传10个 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 将sources和sinks绑定到channels a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动
1 2 3 4 5 6 # Flume要想将数据输出到HDFS,必须持有Hadoop相关jar包(chd版本的已经集成过了,不用管) bin/flume-ng agent -c conf/ -f job/kafka-flume-hdfs.conf -n a1 # 会自动在hdfs上创建文件夹 # 每30s会滚动一个文件,但前提是这30s内有新数据进来 # 去kafka生产者生产点数据,测试一下30s文件滚动的效果
hdfs上的数据效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 文件目录(自动生成) /report-form-data/flume/my-kafka-topic/20191105/16 /report-form-data/flume/my-kafka-topic2/20191105/16 # 目录下的文件 logs-.1572937573119 logs-.1572937799038 logs-.1572937910088 # 数据样式 # logs-.1572937799038 444ddd aaa111 bbb222 ccc333 # logs-.1572937910088 ddd444
解析:hdfs配置中roll 和 round 的解释 1 2 3 4 5 6 7 8 9 10 11 12 # 生产环境下以下配置很重要 # 滚动文件 hdfs.rollInterval hdfs.rollSize hdfs.rollCount hdfs.batchSize # 滚动文件夹(Hive也按天分区) hdfs.round hdfs.roundValue hdfs.roundUnit
解析:按不同topic在hdfs上分目录方案的原理 1、kafka.topics可以配置多个topic,然后hdfs.path的目录设置为/report-form-data/flume/%{topic}/%Y%m%d/%H。
实现思路:kafka发的数据,每个event的headers中有topic字段,其中%{topic}就是取这个字段当目录
1 2 3 4 # 在kafka生产者里生产数据,看logger sink 的接受效果,如下 2019-11-05 14:24:50,615 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{topic=my-kafka-topic, partition=0, timestamp=1572935089618} body: 78 69 78 69 78 69 xixixi } # 如果有更深层的要求需要自己编写flume拦截器代码解析这个字段
测试环境和生产环境下的配置 1 2 # 多久生成一个新的文件,生产环境不要设置30s,太快了 a1.sinks.k1.hdfs.rollInterval = 30
可能遇到的BUG nc客户端无法使用 1 2 3 4 报错:Ncat: Connection refused. # centos7安装netcat: https://my.oschina.net/u/3530967/blog/1560985
TODO 继续以上内容
问题:能同时监控 旧文件追加 和 新文件产生吗 ?
以上都是基于mem channal的
一个对比:
sqoop: 传统关系型数据库(musql) –> sqoop –> 大数据平台(Hadoop hdfs/hive/hbase)
可以写定时器实时增量导入。
定位是数据迁移。导入结构化数据。Sqoop是关系型数据库和HDFS之间的一个桥梁。
Flume:监控文件/文件夹/端口/socket 数据变化 –>Flume –> 大数据平台(Hadoop hdfs/hive/hbase)
定位主要是各种来源的日志采集。








