参考:
[TOC]
与mysql类似,是为业务数据做存储的。
Hbase的应用场景及特点
HBase在实际业务场景中的应用,也就是在学习HBase之前,首页要搞清楚为什么要学习Hbase,学习HBase能在实际业务中解决什么样的问题
Hbase能做什么
- 海量数据存储
- 上百亿行 * 上百万列
- 百万行数据没必要放Hbase,因为没有优势,放mysql就行了
- 准实时查询
- 百毫秒
Hbase在实际业务场景中的应用
交通
- 船舶GPS信息(全长江段GPS信息每天产生1000w左右),用作数据分析,如长江哪一段流量最大。
道路摄像头
金融数据
电商数据(用户行为、交易、物流)
移动(通信记录…)
Hbase的特点
容量大:
- Hbase单表可以有百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性。
- 在传统关系型数据库中,单表一般不超过500w,否则就要考虑分表分库,列不超过30列。
- Hbase 适合存储 PB 级别的海量数据,在 PB 级别的数据以及采用廉价 PC 存储的情况下,
能在几十到百毫秒内返回数据。
面向列:
- Hbase是面向列的存储和权限控制,并支持独立检索。列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字断的时候,能大大减少读取的数据量。
- 关系型的列是定义的时候固定的,Hbase是可以动态增加的。
多版本
- Hbase每个列的数据库存储有多个Version
- 个人信息,如家庭住址,会搬家形成历史住址,这些信息也想存在数据库里,这时可以利用Hbase的version。
- Hbase每个列的数据库存储有多个Version
稀疏性
- 为null的列并不占有存储空间,表可以设计的非常稀疏。
- 以数据为基准动态增加列,但关系型需要以null,空字符串去填充。
扩展性
- 底层依赖HDFS
- 如果磁盘空间不够了,只需要动态增加DataNode节点服务即可。不需要像关系型一样做数据迁移,机器扩展…等等麻烦的操作
- 通过横向添加 RegionSever 的机器,进行水平扩展,提升 Hbase 上层的处理能力,提升 Hbsae
服务更多 Region 的能力。
高可靠性
- WAL机制保证数据写入时不会因集群异常而导致写入数据丢失:Replication机制保证了在集群出现严重问题时,数据不会发生丢失或损坏。而且Hbase底层使用HDFS。
高并发
- 由于目前大部分使用 Hbase 的架构,都是采用的廉价 PC,因此单个 IO 的延迟其实并不
小,一般在几十到上百 ms 之间。这里说的高并发,主要是在并发的情况下,Hbase 的单个
IO 延迟下降并不多。能获得高并发、低延迟的服务。
高性能

Hbase的概念与定位
基于官网对HBase概念的描述,介绍HBase版本的发展及在hadoop2.x生态系统中的定位。
深刻了解Hbase的概念
读官网介绍
选择合适Hbase的版本
企业不会选最新版本,一般选稳定版本
官方版本:选择一直在更新的版本号(说明在不停优化)
CDH版本:对大数据各种架构做了整个集成,稳定性兼容性很好,一般商用会选CDH
认识Hbase在Hadoop2.x生态系统中的定位

Hbase架构体系与设计模型
介绍HBase的整体架构体系与设计模型,了解HBase的表设计和数据模型与以往的关系数据库有什么不同。
Hbase架构体系
Hbase两个重要进程:RegionServer、Master。
2个依赖:HDFS(存储底层)、Zookeeper(分布式协调)
RegionServer:管理Hbase表数据。
当Hbase一个表很大的时候,可以对表分区,一个分区就是一个Region,对应一个RegionServer
Master:RegionServer需要实时报告Master(状态信息等),Master是一个全集管理者,掌握RegionServer集群。
Zookeeper:也会得到RegionServer信息,像Master一样。所以Master可以直接向Zookeeper获取信息。

下面是个更详细的版本
Hbase 架构如图:
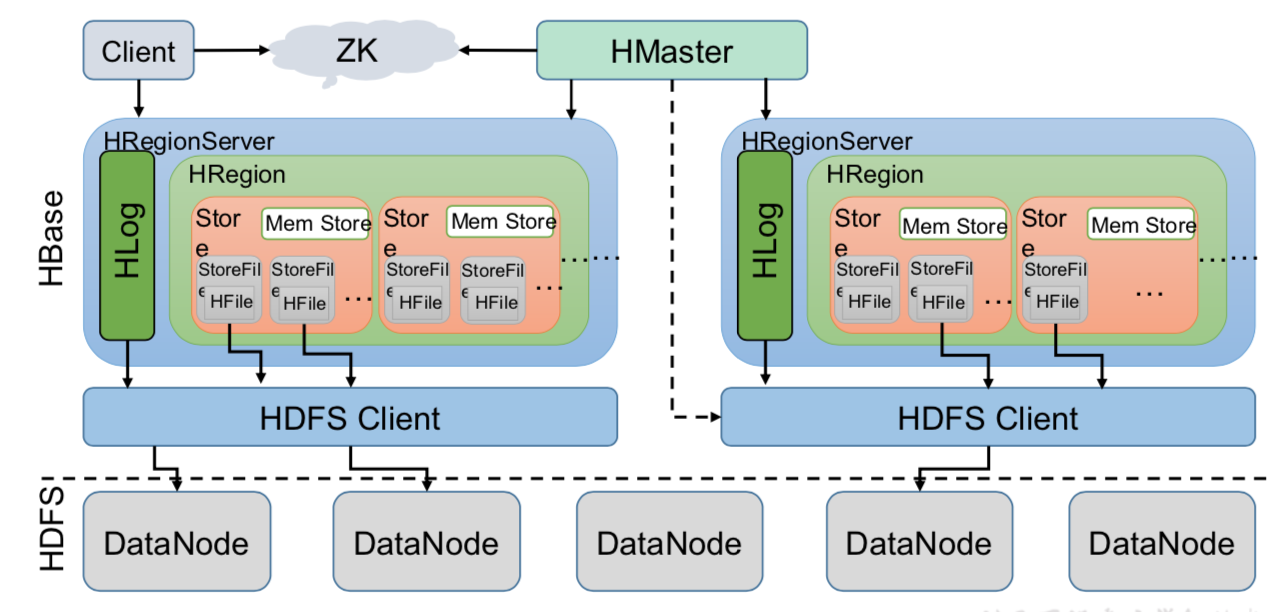
Client
Client 包含了访问 Hbase 的接口,另外 Client 还维护了对应的 cache 来加速 Hbase 的访问,比如 cache 的.META.元数据的信息。
Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、RegionServer 的监控、元数据的入口以及 集群配置的维护等工作。具体工作如下:
通过 Zoopkeeper 来保证集群中只有 1 个 master 在运行,如果 master 异常,会通过竞争 机制产生新的 master 提供服务
通过 Zoopkeeper 来监控 RegionServer 的状态,当 RegionSevrer 有异常的时候,通过回 调的形式通知 Master RegionServer 上下线的信息
通过 Zoopkeeper 存储元数据的统一入口地址
Hmaster
master 节点的主要职责如下:
为 RegionServer 分配 Region
维护整个集群的负载均衡
维护集群的元数据信息
??发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上当 RegionSever 失效的时候,协调对应 Hlog 的拆分
HregionServer
HregionServer 直接对接用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
管理 master 为其分配的 Region 处理来自客户端的读写请求
负责和底层 HDFS 的交互,存储数据到 HDFS 负责 Region 变大以后的拆分
负责 Storefile 的合并工作
HDFS
HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高可用(Hlog 存储在 HDFS)的支持,具体功能概括如下: 提供元数据和表数据的底层分布式存储服务数据多副本,保证的高可靠和高可用性
Region
Hbase 表的分片,HBase 表会根据 RowKey 值被切分成不同的 region 存储在 RegionServer 中,在一个 RegionServer 中可以有多个不同的 region。Store
HFile 存储在 Store 中,一个 Store 对应 HBase 表中的一个列族。 不同的Store放在不同的文件夹里(类似Hive分区)。
memstore刷写一次,就形成一个文件StoreFile;
Write-Ahead logs
HBase 的修改记录,当对 HBase 读写数据的时候,数据不是直接写进磁盘,它会在内 存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的 概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件 中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在 WAL 中之后,RegsionServer 会在内存中存储键值对。
HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。StoreFile 是以 Hfile 的形式存储在 HDFS 的。
Hbase表结构模型
在创建表的时候不需要指定列,只需要指定列蔟(Hbase是面向“列蔟”的数据库)

举例:具体的列可以动态增加,对于每条数据,它的列可能与其他条数据是不同的。

Hbase数据模型
row key:主键
下图说明了面向列的数据库存储方式

举例:

关于列蔟:

Region服务在表大的时候会自动切分,也可以人工干预划分。
Hbase与关系型的对比

列动态增加:查询写入高性能
Hbase不支持条件查询,只支持row key匹配
Hbase的安装部署
非常全面的介绍HBase分布式的安装,一步一步讲解,从HDFS、Zookeeper到HBase,全流程实操演示。
先把zookeeper和Hadoop安装好
安装配置
1 | conf/hbase-env.sh |
启动
1 | cd bin |
Hbase shell的使用
通过shell命令介绍HBse表的操作和表数据的操作
Hbase表操作命令

1 | 进入shell |
Hbase表数据操作命令

1 | 对行数求和 |
总结
TODO
元数据






